hey @elgiano ![]()
thank you for nn.ar!
just to add to the conversation, I tested it here using RAVE provided models, I seem to have no dropouts even with lower buffer sizes ![]()
running on ArchLinux, ThinkPad t14s gen 3.
hey @elgiano ![]()
thank you for nn.ar!
just to add to the conversation, I tested it here using RAVE provided models, I seem to have no dropouts even with lower buffer sizes ![]()
running on ArchLinux, ThinkPad t14s gen 3.
Buffer size seems to depend a whole lot on which model I’m using – with the “wheel” model I was able to run
(
{
var in = SoundIn.ar(0) * 12;
var out = NN.ar(\wheel, \forward, 128, in);
out;
}.play
)
and it didn’t glitch out too much (though it was spiky – and oddly the low buffer size didn’t seem to make a big difference in realtime delay, i.e. the delay was still quite noticeable, though I didn’t test extensively)
but with “vintage” model I ran
{
var in = PlayBuf.ar(1, c, BufRateScale.kr(c), loop:0);
var latent = NN.ar(\vintage, \encode, 2048*8, in * 6);
var mod = latent.collect { |l| l + LFNoise1.ar(1).range(-1, 1) };
NN.ar(\vintage, \decode, 2048*8, mod)!2;
}.play;
(which was about as high as I could go before I got error messages) and still it wasn’t able to render in realtime, I just recorded the server output and turned down my speakers.
Here is my as-is m1 build in case it’s helpful to others:
https://drive.google.com/drive/folders/1lsxMF8eNkPXI0uVJdh2ZefEEVg4_PL43?usp=sharing
I compiled nn.ar for windows to test, here is the compiled plugin in case someone wants to try it out ![]()
https://bgo.la/nn-ar-win-build.zip
I had zero experience compiling things on windows, so you might need to add the .ddl files from libtorch in the same folder as your scsynth.exe ( i used https://download.pytorch.org/libtorch/cpu/libtorch-win-shared-with-deps-2.0.1%2Bcpu.zip )
thanks @bgola and @Eric_Sluyter for your builds!
I added GitHub actions, so that builds are now generated automatically for linux, mac-x64 mac-arm64 and windows. However I haven’t tested any of them (I have no access to mac or win machines at the moment). Would you mind testing them?
I also polished a bit interfaces and documentation. I’ve tried some NRT synthesis and it sounds good (no dropouts) as I would have expected. So, if RT is not really viable for “weaker” computers (like mine), at least we have more expressive tools to do NRT renders.
@scztt (and everyone interested): I have more time this week, would you like to have a look at the cpp code and sc interfaces together?
Yes, maybe we do a code review togethert? I’ll DM you tomorrow when I can figure out my schedule but this would be fun.
Hey all!
I’ve released v0.0.2-alpha (![]() )
)
Apart from it fixing some release issues, it includes recent updates to nn_tilde, and some optimizations that made it lighter on the dsp chain. With this I mean it became more async, so if the processing thread takes too long you’ll get silences in NN.ar output, but not freeze the rest of the audio chain.
Let me know how it goes if you try it!
Hey all!
Version v0.0.3-alpha is out (![]() )
)
Fixed some issues and changed the interface a little little bit.
Let me know how it goes if you try it!
I’ve added some considerations about latency to the README, I thought it could be nice to share them here too:
RAVE models can exhibit an important latency, from various sources. Here is what I found:
tl;dr: if latency is important, consider training with --config causal.
--config causal, which reduces this latency to about 5ms, at the cost of a “small but consistent loss of accuracy”.Thanks for this. I experienced dropouts with the prior version, but this one seems better and I have no drops.
On my Mac M1 max and OS 13.3.1, the following does not work:
// 2. play
{ NN(\rave, \forward).ar(1024, WhiteNoise.ar) }.play;
However, this from your helpfile, works:
{ NN(\rave, \forward).ar(WhiteNoise.ar) }.play
Adam
Hi Adam!
with version 0.0.3 I changed the interface a little bit: so now the first argument to .ar is inputs, and not blockSize anymore, which was moved to be the second argument.
So the new syntax is:
NN(model, method).ar(inputs, blockSize, ...)
This is why your second example works and the first doesn’t work anymore. I hope I have updated the documentation in all places ![]()
Happy your dropouts got better! Just out of curiosity, are you using a pretrained model or did you train your own?
Got it! I think your Github Readme still uses the old format, but I should use the SC help files anyway.
I am using pretrained models for testing for now, but hope to train my own soon.
Speaking of pretrained models: I am using the ones from here: https://acids-ircam.github.io/rave_models_download . If I understand correctly, in these .ts files, the prior is part of the file, instead of separate. In your implementation, is there a way of using the prior of these particular files, rather than loading a separate prior?
Again, thanks so much for the work on this!
Sure, it’s just another method. Old Rave prior is a method with 1 input (temperature) and “latent size” outputs. It outputs latent codes, so you need to decode them:
var temp = MouseY.kr.range(0,10);
var latent = NN(\rave, \prior).ar(temp);
NN(\rave, \decode).ar(latent);
By the way you can check if a model has a prior method (not all of them do):
NN(\rave).methods
I’ll update the README asap! I thought i did but maybe something went wrong, sorry for the confusion!
Excellent, this works, thanks so much!
I found, that for at least the prior of the VCTK.ts model, the latent codes need a multiplication factor of larger than 1 in order for the decoder to keep outputting audio. This is not the case with the prior of vintage.ts.
In case anyone missed it, we released 15 RAVE models recently:
My TidalCycles / SuperDirt integration is now based on NN.ar:
Thanks for sharing the models and releasing code for transfer learning! Can I ask what your experience is concerning transfer learning - I was surprised that this seems not the default way of training for rave.
Can I also ask something regarding training models?
I trained one model on around 5 to 10 minutes of spoken text by different people. Considering the amount of parameters I would say that this is maybe not enough data, but also the paper doesn’t say anything about these aspects.
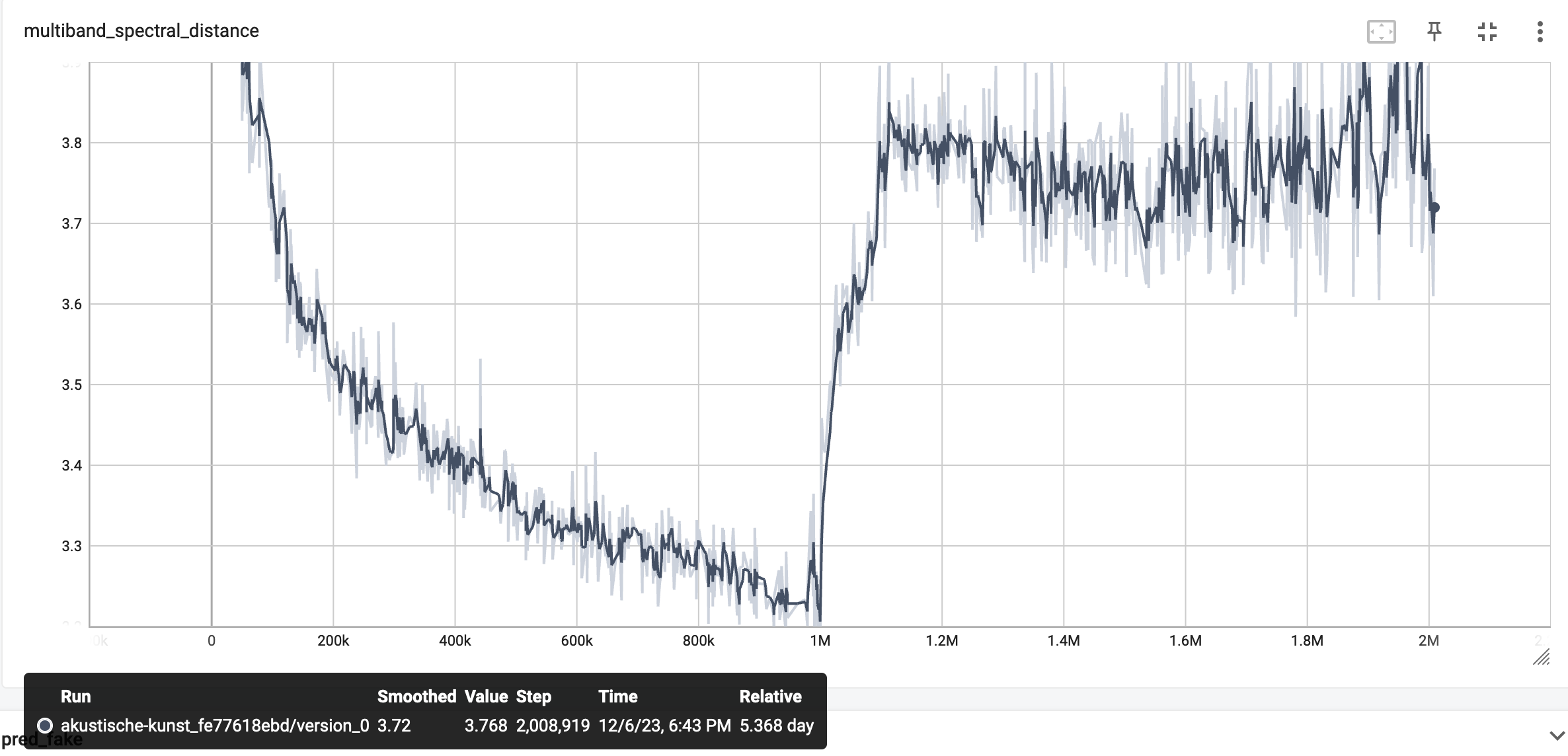
I trained it within 5 days on a 3080 for 2M steps and the multiband spectral distance developed like this - which looks somehow fine I think? At least it is clear that the 2nd step of tuning the decoder started.
Yet the outcome sounds really off - like extreme tape wobble - and the input is here a sample from the dataset which is a really clean recording of a male voice, it is not even recognizable what the person is saying. And this is at fidelity 0.99.
5-10mins definitely not enough for RAVE, you would need minimum 2hrs and ideally 4-10hrs or more.
In general, I would recommend reading/asking on the RAVE Discord: RAVE
Thanks for the reply.
BTW - do you have any checkpoints for the voice models? I only found them for the 2 organ models.
It’s a pity that more and more information gets locked behind Discord ![]()
We don’t as we’re in the early days of evaluating models created via transfer learning, but there will likely be more in future.
But the goal of transfer learning / “foundation models” is that you don’t need to be in the same stylistic domain. Our transfer learned models so far have been in voice, percussion, electronic, acoustic instruments, and they work extremely well, especially considering they only take hours to train instead of days/weeks.
To stay up to date with our work you can join our Discord: Intelligent Instruments
But only if the dataset contains high enough variance, right? I already wondered why there has not been a “big universal” model from which you do transfer learning? Is the model not capable of handling so much variety?
Also - do you know if someone looked at conditioning the VAE? I think this would allow for more precise movement within the latent space. I will try looking into it, but most likely ditch the dynamic latent space dim-reduction algorithm while at it.