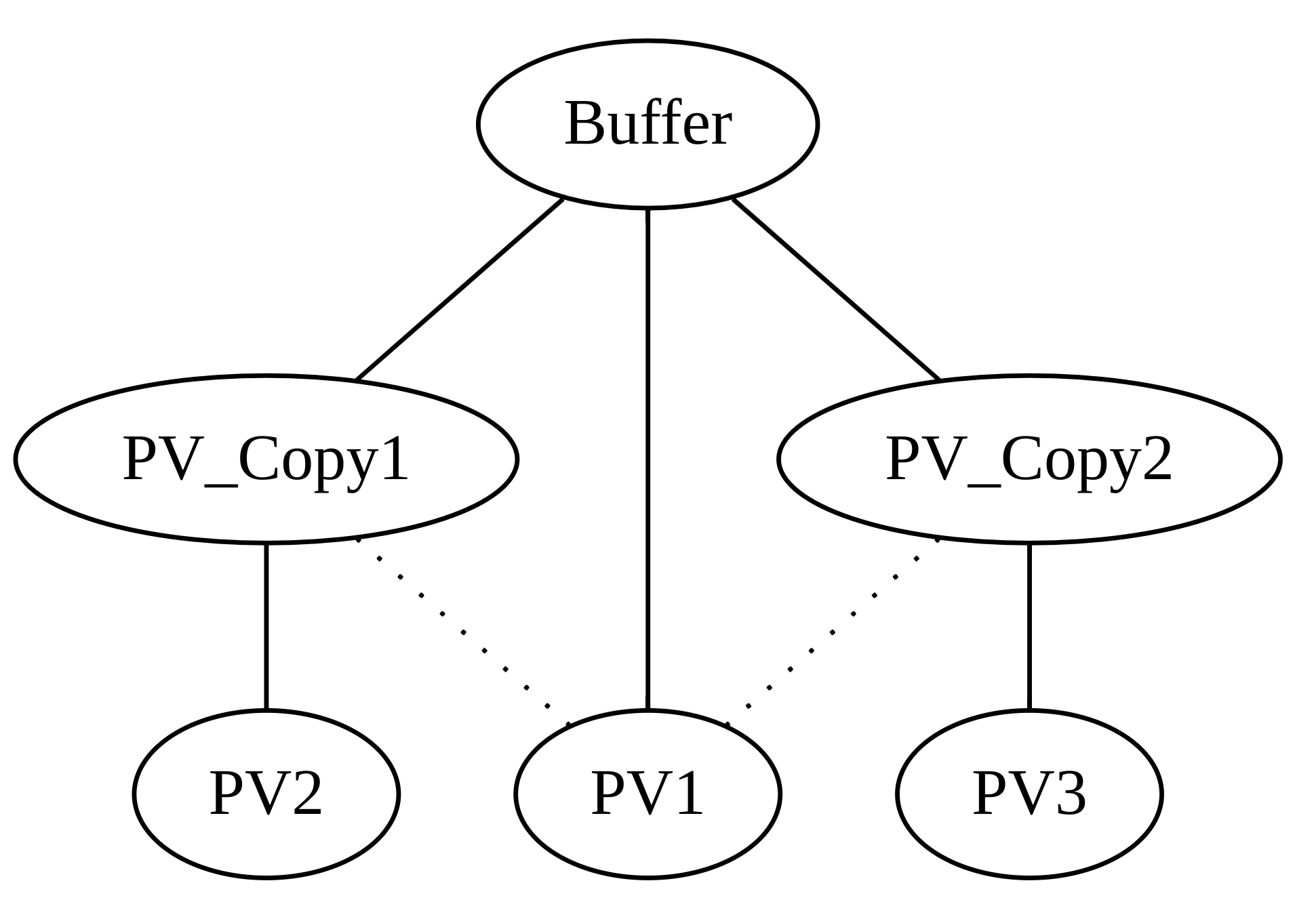
This sounds like a great and – in hindsight! – obvious solution. Some UGens have implicit interdependencies and expressing these with additional graph edges makes them visible to the graph sorting algorithm.
BTW, some of these dependencies cannot be automatically deduced and need to expressed explicitly by the user. One common example is a BufWr followed by a BufRd:
var sig = SinOsc.ar;
var phase = Phasor.ar(0, 1, 0, BufFrames.kr(buf));
var writer = BufWr.ar(sig, buf, phase);
var reader = BufRd.ar(1, buf, phase - 44100, loop: 1);
(Taken from firstArg question - #2 by jamshark70)
Nothing in the example above guarantees that BufWr is scheduled before BufRd.
Currently, the workaround is to use the (rather obscure) !< operator:
var sig = SinOsc.ar;
var phase = Phasor.ar(0, 1, 0, BufFrames.kr(buf));
var writer = BufWr.ar(sig, buf, phase);
var reader = BufRd.ar(1, buf <! writer, phase - 44100, loop: 1);
This ensures that BufWr runs before BufRd. Note that <! actually creates a BinaryOpUGen with the operator firstArg which just discards the second argument.
I think a better solution would be to have a method that adds a “weak edge” between two UGens, e.g.:
var sig = SinOsc.ar;
var phase = Phasor.ar(0, 1, 0, BufFrames.kr(buf));
var writer = BufWr.ar(sig, buf, phase);
var reader = BufRd.ar(1, buf, phase - 44100, loop: 1).after(writer);
IMO this is much easier to understand than the <! operator. Also, it wouldn’t require an additional UGen.