@scztt Should Quark2 be implemented in supercollider? Are we using Quark2 to update the core library, and with it, Quark2 itself? Wouldn’t a tool that doesn’t depend on supercollider running be better?
Never really understood why Quark wasn’t a separate program to begin with as you have to recompile the class library anyway.
Some people have mentioned that install git on windows is a little more involved than elsewhere. Perhaps something standalone could be made, perhaps in go using GitHub - go-git/go-git: A highly extensible Git implementation in pure Go. ?
Thought it might be fun to try and map the dependencies within the current scclasslibrary by looking for class names directly reference in the source code.
I think splitting apart the existing class library without breaking anything will be harder that expected/require many class extensions which might make it harder to reason about the code.
The regex I’ve used will match things in comments (would be nice to have a sclang parser in sclang!), but seems pretty good. It also doesn’t matching things like thisProcess which implies a dependency on Main.
Obviously everything also depends on Object as well.
Here is files that reference other files.
sc
~getNicePath = {|str| str.asString.split($/)[6..].reduce('+/+') };
~getMentionedClasses = {|class|
[class.asSymbol, ~getNicePath.(class.filenameSymbol.asString)] ->
File.readAllString(class.filenameSymbol.asString)
.findRegexp("[ ({][A-Z][a-zA-Z0-9_]+")
.collect({|n|
n[1]
.reject([$ , $(, ${].includes(_) )
.asSymbol
})
.reject({|n|
n.asClass.isNil
})
.collect({|c|
[c, ~getNicePath.(c.asClass.filenameSymbol)]
})
.asSet
};
~r = Class.allClasses
.reject(_.isMetaClass)
.collect({|c| ~getMentionedClasses.(c, ) })
.asEvent;
t = TreeView().front;
t.columns_(["Class", "File"]);
~r.keysValuesDo({|k, v|
var i;
t.addItem([k[0].asString, k[1].asString]);
i = t.itemAt(t.numItems - 1);
v.do({|ar|
i.addChild([ar[0].asString, ar[1].asString])
})
});
t.canSort = true;
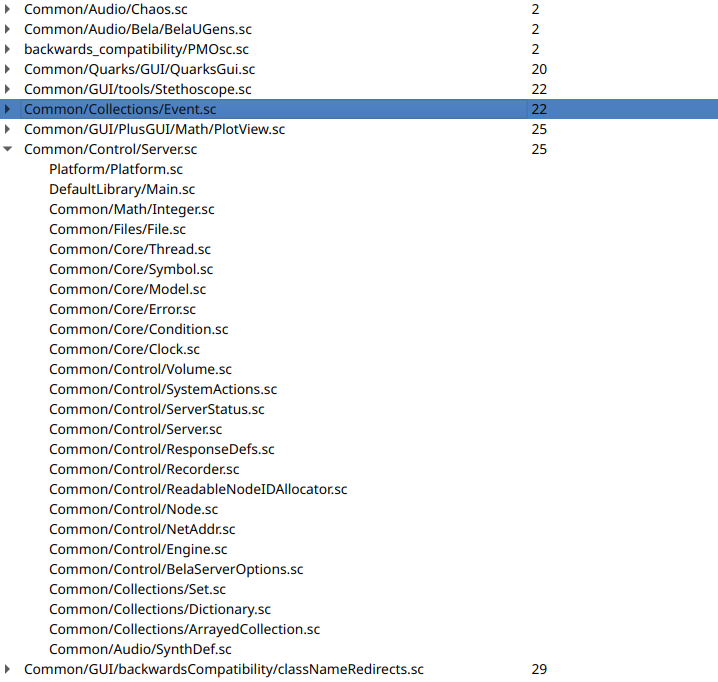
Here is Classes referencing other classes
sc
(
~getNicePath = {|str| str.asString.split($/)[6..].reduce('+/+').asSymbol };
~getFileConnections = {|class|
~getNicePath.(class.filenameSymbol.asString) ->
File.readAllString(class.filenameSymbol.asString)
.findRegexp("[ ({][A-Z][a-zA-Z0-9_]+")
.collect({|n|
n[1]
.reject([$ , $(, ${].includes(_) )
.asSymbol
})
.reject({|n|
n.asClass.isNil
})
.collect({|c|
~getNicePath.(c.asClass.filenameSymbol)
})
.asSet
};
~r = Class.allClasses
.reject(_.isMetaClass)
.collect({|c| ~getFileConnections.(c, ) })
.asEvent({|a, b| (a ++ b).asSet });
t = TreeView();
t.columns = ["File", "Count" ];
~r.keysValuesDo({|k, v|
var i = t.addItem([k.asString, nil]);
v.do({|c| i.addChild([c]) });
i.setString(1, v.size.asString);
});
t.canSort = true;
t.itemPressedAction({|a|
a.postln
});
t.front;
)
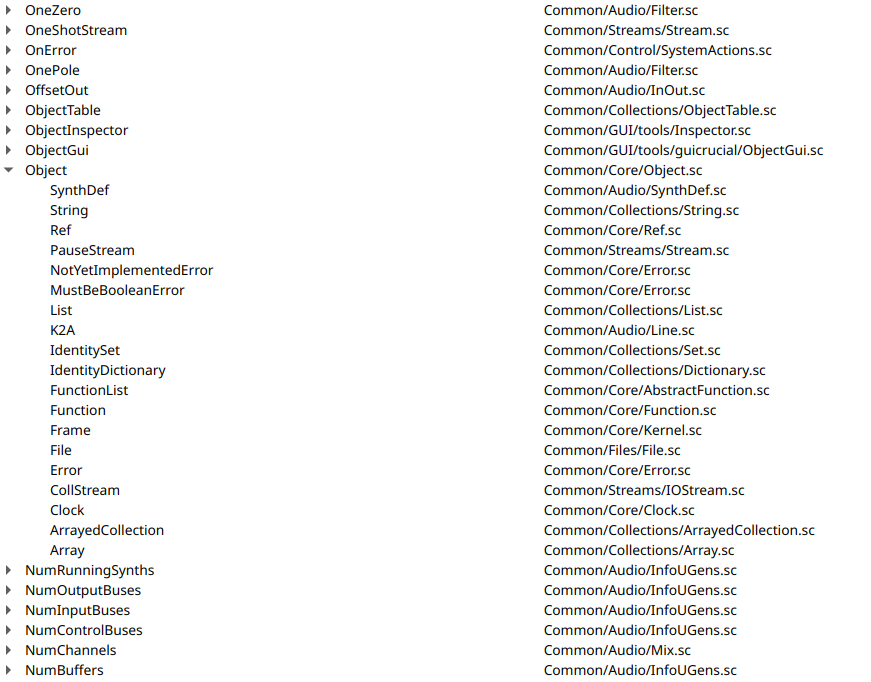
As graphs…
Directories referencing directories, the arrows means ‘references’, so an incoming arrow means ‘is a dependant’.
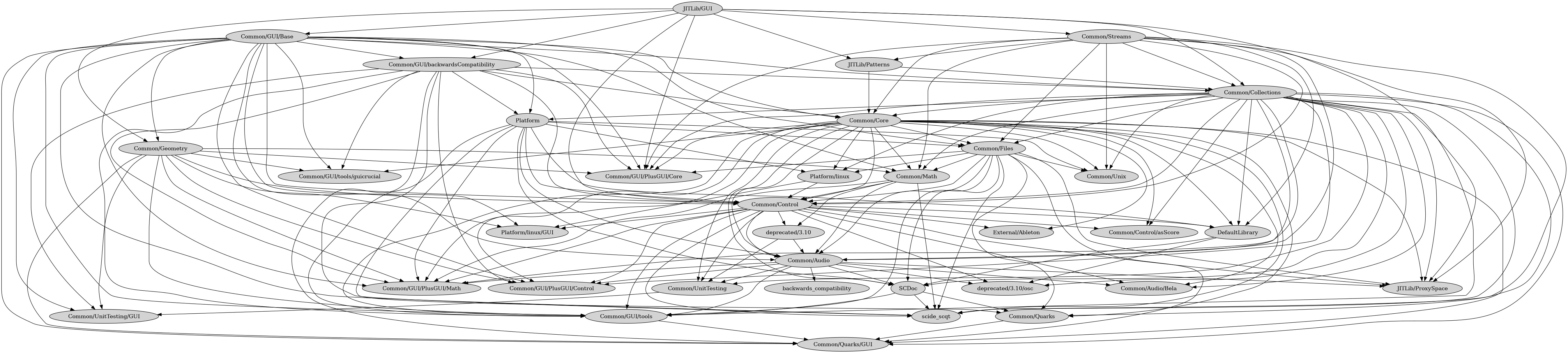
And then, just for fun, classes…
