Since it came up a couple of times (the idea that it’s better for users to write pre-optimized code): One case where I very much appreciate CSE optimization is repeated calls to linlin, linexp or lincurve.
(
SynthDef(\redundancy, { |out, outLow = 1, outHigh = 10|
var lfos = NamedControl.kr(\lfos, Array.fill(10, 0));
Out.kr(out, lfos.linlin(-1, 1, outLow, outHigh));
}).add.dumpUGens;
)
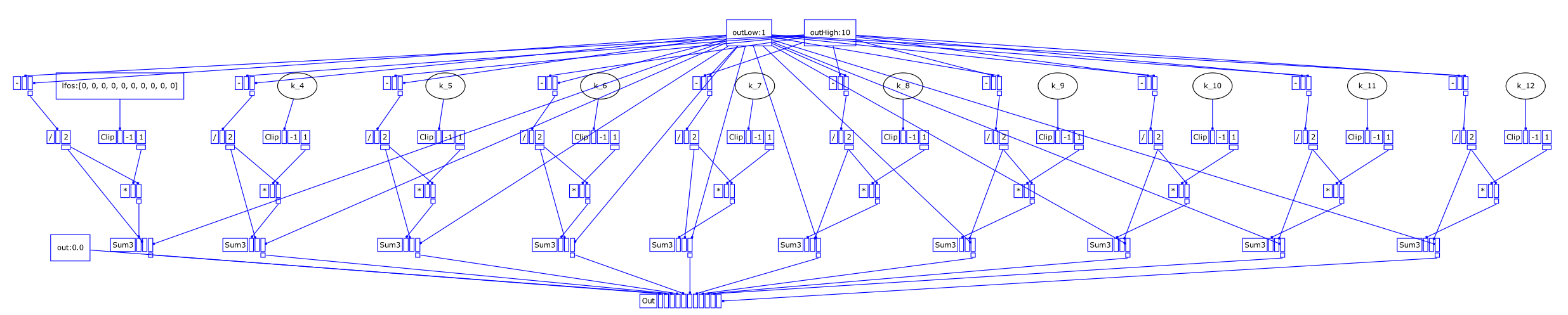
Current dev:
[0_Control, control, nil]
[1_-, control, [0_Control[2], 0_Control[1]]]
[2_/, control, [1_-, 2]]
[3_-, control, [0_Control[2], 0_Control[1]]]
[4_/, control, [3_-, 2]]
... repeated exactly(!) for 10 channels
[21_Control, control, nil]
[22_Clip, control, [21_Control[0], -1, 1]]
[23_*, control, [22_Clip, 2_/]]
[24_Sum3, control, [23_*, 2_/, 0_Control[1]]]
[25_Clip, control, [21_Control[1], -1, 1]]
[26_*, control, [25_Clip, 4_/]]
[27_Sum3, control, [26_*, 4_/, 0_Control[1]]]
... these cannot be optimized out: 10 channels, OK
[52_Out, control, [0_Control[0], 24_Sum3, 27_Sum3, 30_Sum3, 33_Sum3, 36_Sum3, 39_Sum3, 42_Sum3, 45_Sum3, 48_Sum3, 51_Sum3]]
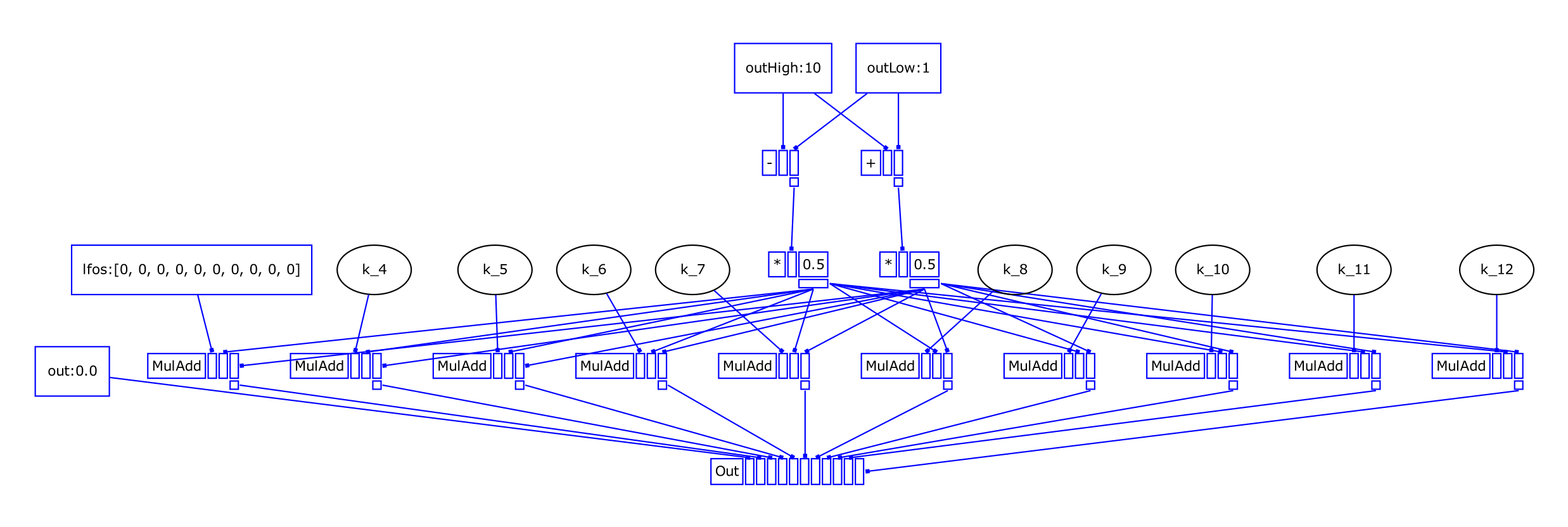
Using my UGenCache (private extension):
[0_Control, control, nil]
[1_-, control, [0_Control[2], 0_Control[1]]]
[2_/, control, [1_-, 2]]
[3_neg, control, [2_/]]
[4_-, control, [0_Control[1], 3_neg]]
[5_Control, control, nil]
[6_Clip, control, [5_Control[0], -1, 1]]
[7_MulAdd, control, [6_Clip, 2_/, 4_-]]
[8_Clip, control, [5_Control[1], -1, 1]]
[9_MulAdd, control, [8_Clip, 2_/, 4_-]]
(required channel calculations...)
[26_Out, control, [0_Control[0], 7_MulAdd, 9_MulAdd, 11_MulAdd, 13_MulAdd, 15_MulAdd, 17_MulAdd, 19_MulAdd, 21_MulAdd, 23_MulAdd, 25_MulAdd]]
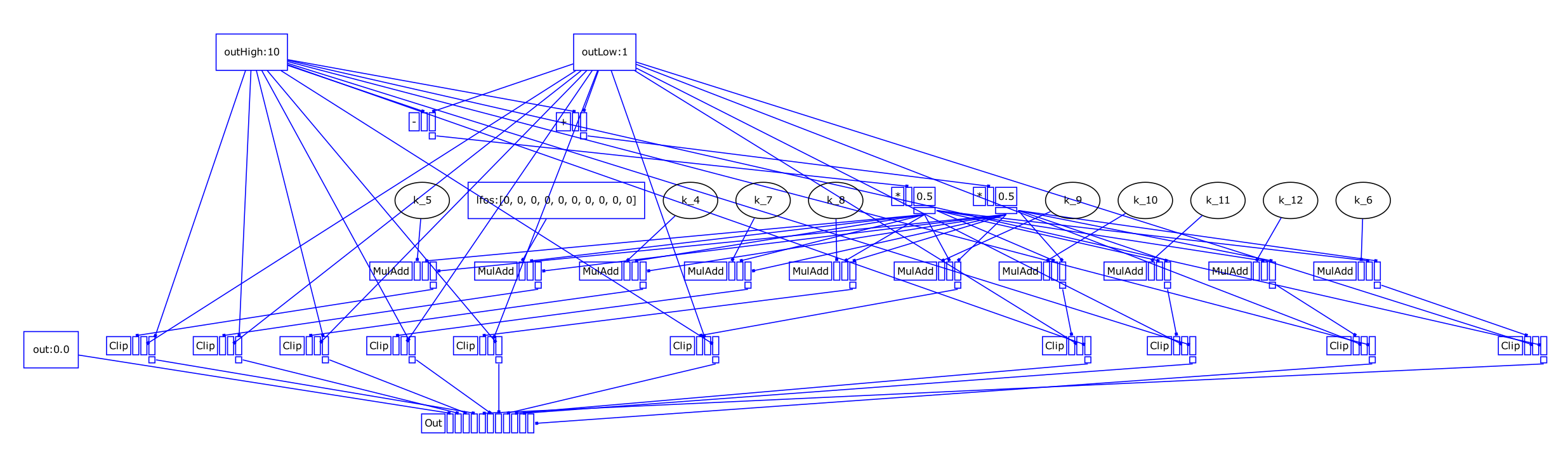
Using Jordan’s dup-smasher (which curiously ends up with 3 units per channel, rather than the 2 that mine manages – I think this is because my approach never enters the duplicate math operations into the graph at all – if instead you have the graph with redundancies, then apply Sum3 optimization, then remove duplicate units, this specific case ends up being less efficient – this underscores a point Scott Wilson raised a little while ago, that it’s extremely difficult to come up with an optimization strategy that handles every case optimally):
[0_Control, control, [0.0, 1, 10]]
[1_-, control, [0_Control[2], 0_Control[1]]]
[2_/, control, [1_-, 2]]
[3_Control, control, [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
[4_Clip, control, [3_Control[0], -1, 1]]
[5_*, control, [4_Clip, 2_/]]
[6_Sum3, control, [5_*, 0_Control[1], 2_/]]
[7_Clip, control, [3_Control[1], -1, 1]]
[8_*, control, [7_Clip, 2_/]]
[9_Sum3, control, [8_*, 0_Control[1], 2_/]]
... channels...
[34_Out, control, [0_Control[0], 6_Sum3, 9_Sum3, 12_Sum3, 15_Sum3, 18_Sum3, 21_Sum3, 24_Sum3, 27_Sum3, 30_Sum3, 33_Sum3]]
To hand-optimize it, you have to do this. (The lincurve formula is quite a bit more complex = inconvenience for looking up the formula, and more chances to make mistakes.)
(
SynthDef(\subexpression, { |out, outLow = 1, outHigh = 10|
var lfos = NamedControl.kr(\lfos, Array.fill(10, 0));
var scale = (outHigh - outLow) / 2;
var offset = 1 - (scale * -1);
Out.kr(out, lfos.clip(-1, 1) * scale + offset);
}).add.dumpUGens;
)
… or, SC could implement linlin/linexp/lincurve for arrays, and pre-optimize there. At least, I think here, the user shouldn’t be burdened with this.
Another case would be multiChannel.collect { |chan| chan = BLowPass4.ar(chan, ...); chan = AnotherOp.ar(...); chan }.
FWIW, the existence of optimizations doesn’t prevent the user from hand-optimizing (which I still do, in some places – the fact that I experimented with a UGenCache for limited CSE doesn’t mean that I now deliberately write redundant subexpressions).
hjh