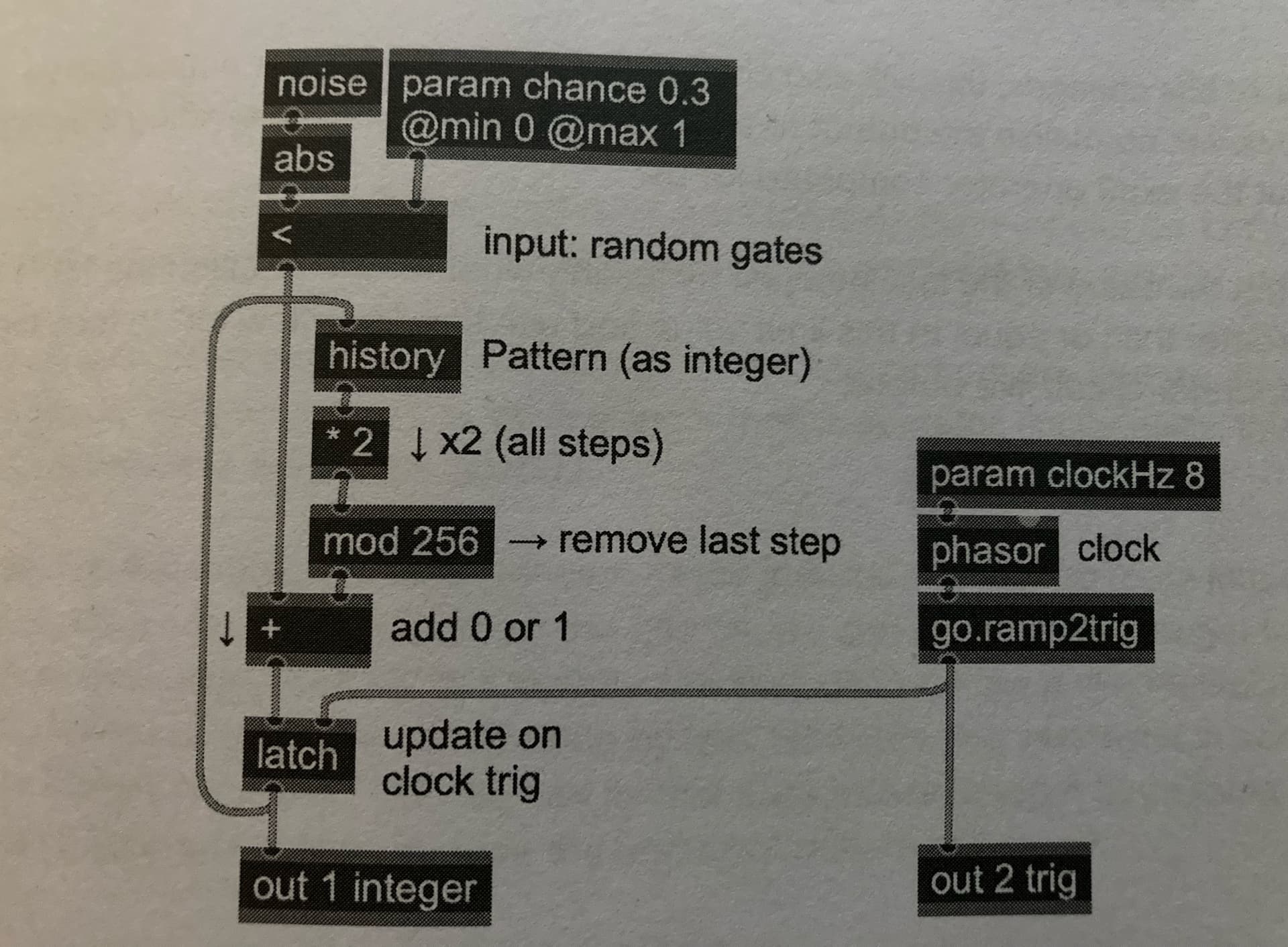
hey, in the book “generating sound & organising time - thinking with ~gen” is an example how to implement a basic 8-bit shift register in ~gen and some further examples how to implement binary decoding and some further extensions like limiting, extraction, rotation. inversion etc… One oberservation from the book is that binary encoding encodes a unique integer for every different possible sequence of bits, and vice versa: every integer encodes a unique gate pattern, so that the entire pattern can be represented as a single integer at any time.
So the same results could be produced just by a few operations on integer signals rather then shuffling gates through a series of shift registers. It is stated that every clock step shifts each gate one step to the right, which effectively doubles its contribution to the output. That would be equivalent to multiplying the whole integers by two. The first step input then adds a new gate either 0 or 1 to the sum. To keep the range of 0 to 255 a modulo operator is used.
For each clock trigger, the currently stored integer (equivalent to shifting the entire binary pattern right by 1 step) is doubled; and a new input (which is either 0 or 1) is added, and then any additional bits beyond stage 8 are removed by using a modulo operator.
Could someone help me out to implement the basic single sample feedback loop with Demand Ugens (Dbufrd and Dbufwr) to create it in SC? Im not sure how the Latch Ugen could be implemented in the single sample feedback path in SC. After that a Xor gate is added for a LFSR and some interesting other techniques to work with the bits of an integer. But thats the basic patch in ~gen:
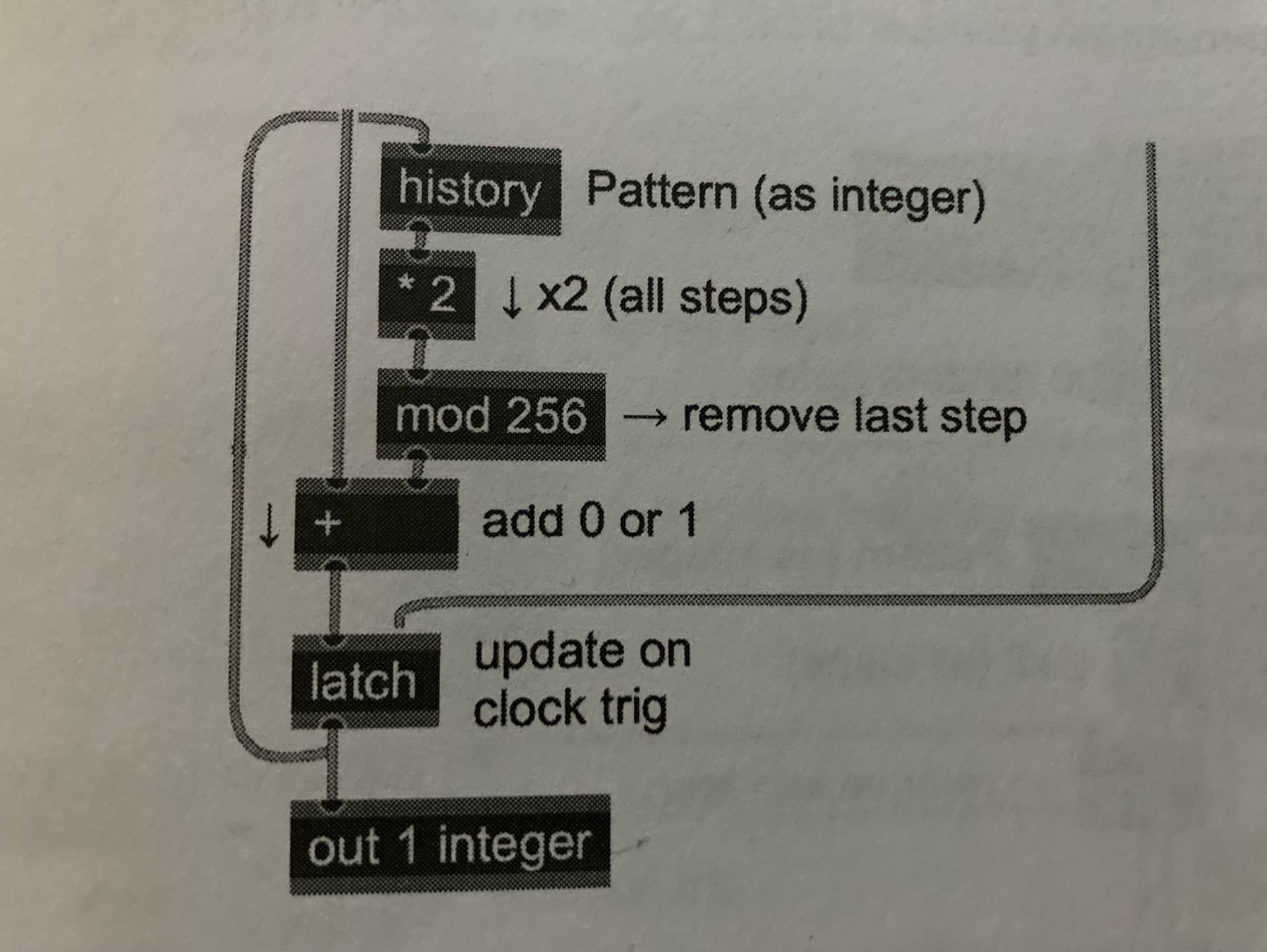
with input source and clock added: