I have used multiple servers on one machine and also used Supernova, and I find Supernova easier to use. Please compare the following three cases and let me know if I have done something wrong!
1. Using multiple servers:
Step 1:
(
fork {
Server.killAll;
Server.scsynth;
4.do { |i|
var thisServerKey = ("s" ++ i).asSymbol;
var thisServerName = ("localhost" ++ i).asSymbol;
var thisServerAddr = 58112 + i;
var thisServerEnvVar = ("~" ++ thisServerKey).asString;
var thisServerDefaultSynthName = ("default" ++ i).asSymbol;
currentEnvironment.put(
thisServerKey,
Server(thisServerName, NetAddr("localhost", thisServerAddr))
);
defer { thisServerEnvVar.interpret.makeWindow };
thisServerEnvVar.interpret.waitForBoot{
SynthDef(thisServerDefaultSynthName, { arg out=0, freq=440, amp=0.1, pan=0, gate=1;
var z;
z = LPF.ar(
Mix.new(VarSaw.ar(freq + [0, Rand(-0.4,0.0), Rand(0.0,0.4)], 0, 0.3, 0.3)),
XLine.kr(Rand(4000,5000), Rand(2500,3200), 1)
) * Linen.kr(gate, 0.01, 0.7, 0.3, 2);
OffsetOut.ar(out, Pan2.ar(z, pan, amp));
}, [\ir]).send(Server.named.at(thisServerEnvVar));
//thisServerEnvVar.interpret.plotTree // Window should be rearranged
};
};
}
)
Step 2:
(
~test = fork {
inf.do { |f|
var nth = (f % 4).asInteger;
var thisServerEnvVar = ("~s" ++ nth);
(
server: thisServerEnvVar.interpret,
instrument: (\default ++ nth).asSymbol,
degree: rrand(0.0, 12.0).round(1 / 4),
db: rrand(-30, -25),
pan: rrand(-1.0, 1.0)
).play;
0.0014.wait;
};
}
)
~test.stop
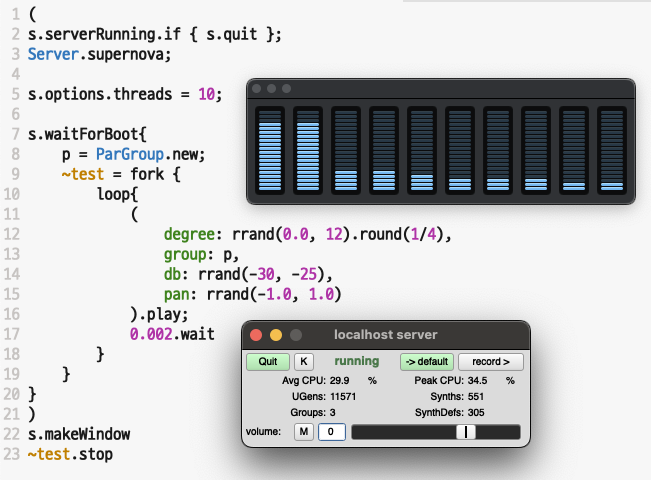
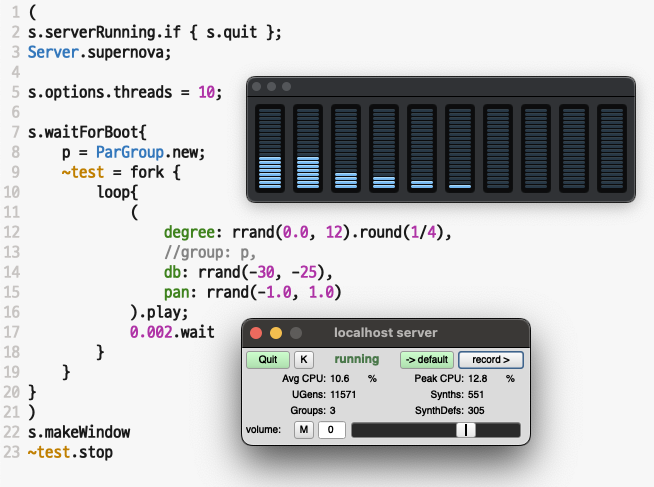
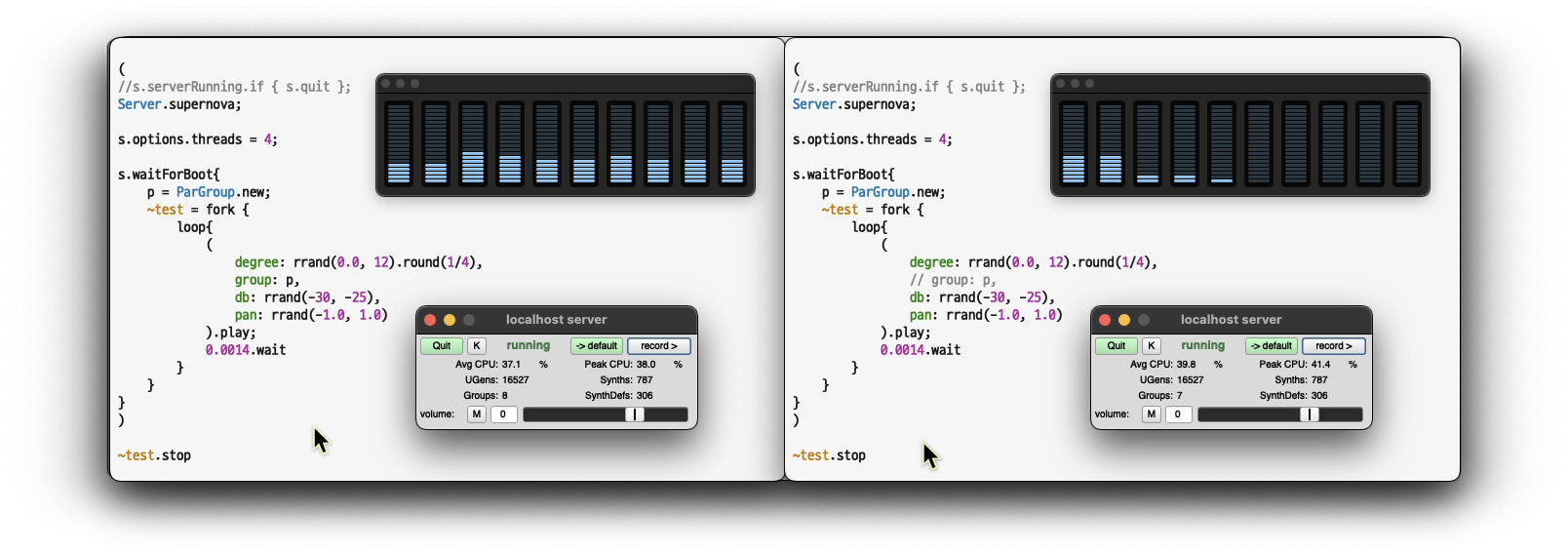
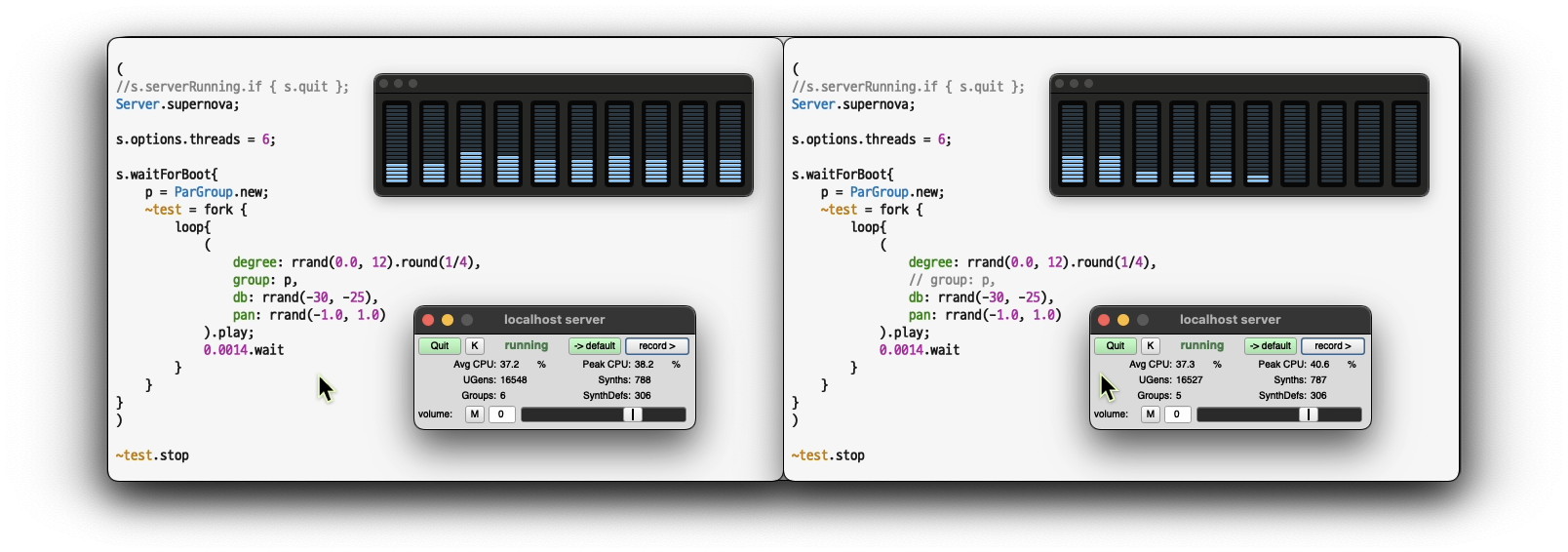
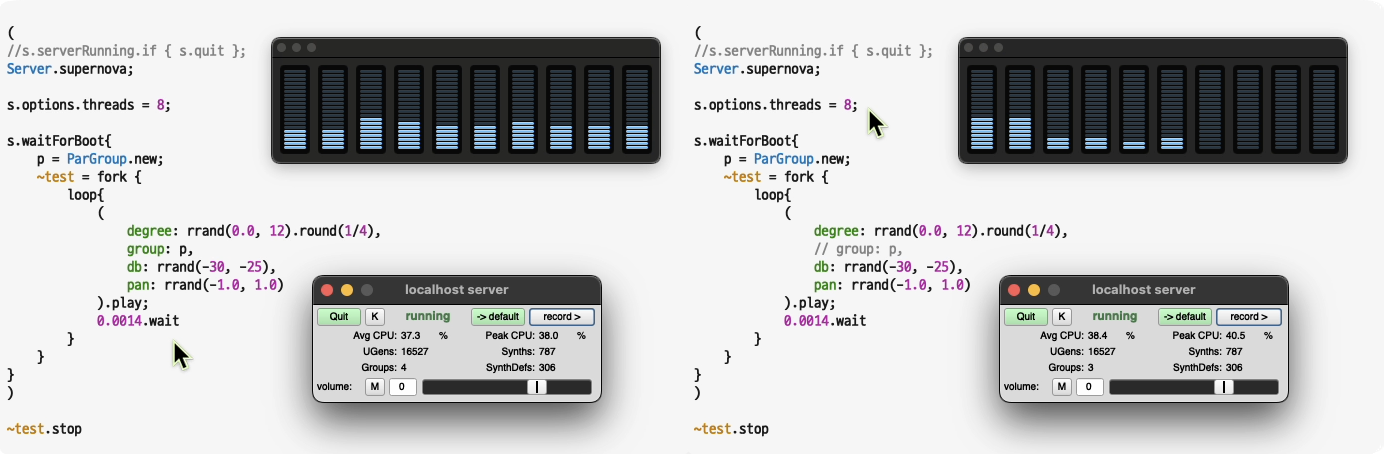
2. Using a supernova:
(
s.serverRunning.if { s.quit };
Server.supernova;
s.options.threads = 8;
// Number of threads to use on the CPU.
// Depending on the number of cores on your machine.
s.waitForBoot{
p = ParGroup.new;
~test = fork {
loop{
(
degree: rrand(0.0, 12).round(1/4),
group: p,
db: rrand(-30, -25),
pan: rrand(-1.0, 1.0)
).play;
0.0014.wait
}
}
}
)
~test.stop
3. Using a scsynth:
(
s.serverRunning.if { s.quit };
Server.scsynth;
// s.options.threads = 4
// Not applicable when using scsynth.
s.waitForBoot{
g = Group.new;
~test = fork {
loop{
(
degree: rrand(0, 12.0).round(1/4),
group: g,
db: rrand(-30, -25),
pan: rrand(-1.0, 1.0)
).play;
0.0014.wait
}
}
}
)
~test.stop