Dear team,
Hope this mail finds well. This is my first programming language I’m learning and have learnt(self-taught) the basics of SC using The SuperCollider Book, Youtube and scsynth forums. I’m trying to do a project based on Digital Signal Processing (DSP) using FFT’s (Fast Fourier Transform UGen). I’ve looked at forums, help files on SCIDE, created my own question(FFT processing using SoundIn and an audio track) – but couldn’t get an complete understanding/answer to what I need to do.
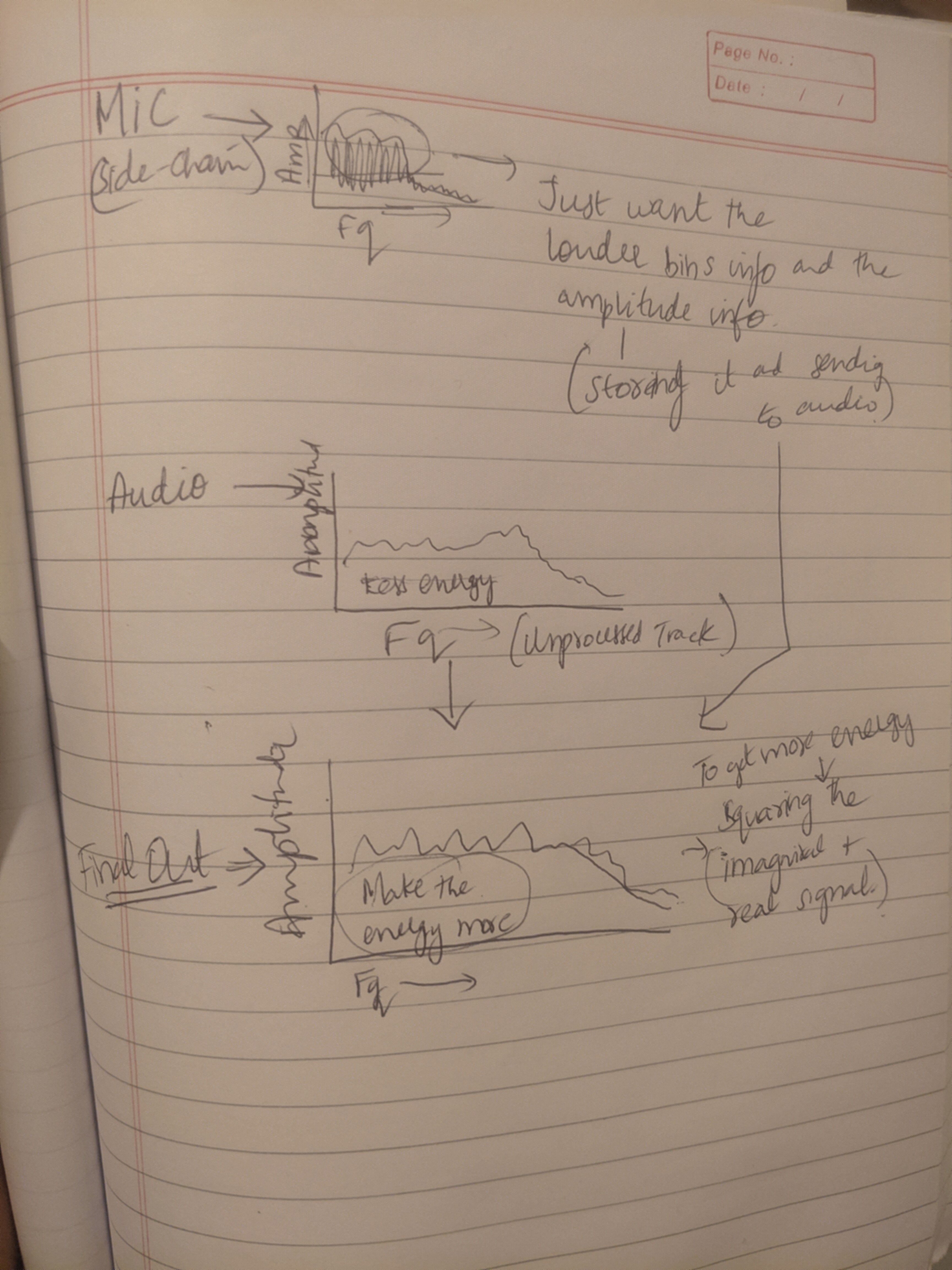
My idea → Take 2 inputs:

- Input from internal mic
- An audio track being played through a buffer.
Do real-time FFT processing with input mic and an audio track.
I think I got a flow diagram as above from online (https://stash.reaper.fm/37301/STFT%20sketch%20small.png) and thinking of applying the exact concept.
So my idea is to play the audio track and affect the phase (once I get an working template, I can do other processing by modifying the parameters or doing something different) from the input mic to create an experimental audio out track.
So far, I have figured out playing with fft bins (audio and mic separately). I’m stuck here not knowing:
1)How to combine them, 2) Compare audio and mic fft using a loop or something and then 3) Modifying(processing) one with another. Could you please please help me in this regard and point me at the right direction? I’m desperate to get a working model by end of this year if possible please 
s.boot;
//Mic Input processing - without using synthdef
(
x= {
var sig, chain, size=2048;
sig=SoundIn.ar(0, 1);
chain= FFT(LocalBuf(size), sig, 0.5, 0);
chain = PV_BinScramble(chain, \wipe.kr(0), \width.kr(0), \trig.tr(0)); // Processsing to be done
sig=IFFT(chain)*0.1!2;
}.play;
)
x.set(\wipe, 0.8, \width, 0.2, \trig, 1);
x.free;
//Audio FFT processing using SynthDef
~buf = Buffer.read(s,"/Users/Kirthan/Desktop/real.wav"); //choose any audio file
(
SynthDef(\fftaudio, {
arg loop=1, da=0;
var sig, chain, size=2048;
sig = PlayBuf.ar(1, \buf.kr(0), BufRateScale.ir(\buf.kr(0)), loop:loop, doneAction: da);
chain = FFT(LocalBuf(size), sig);
chain = PV_BinScramble(chain, \wipe.kr(0), \width.kr(0), \trig.tr(0)); //Processing to be done
sig = IFFT(chain) * \amp.kr(0.5)!2;
Out.ar(\out.kr(0), sig);
}).add;
)
a = Synth(\fftaudio, [\buf, ~buf]);
a.set(\loop, 0, \da, 2);
a.set(\wipe, 0.5, \width, 0.1, \trig, 1);
a.free;
//Mic FFT proccessing using SynthDef
(
SynthDef(\fftmic, {
var sig, chain, size=2048;
sig=SoundIn.ar(0, 1);
chain= FFT(LocalBuf(size), sig, 0.5, 0);
chain = PV_BinScramble(chain, \wipe.kr(0), \width.kr(0), \trig.tr(0)); //Processing to be done
sig = IFFT(chain) * \amp.kr(1)!2; // Amplitude set to unity gain - Please reduce or use it with caution!!!
Out.ar(\out.kr(0), sig);
}).add;
)
m = Synth(\fftmic);
m.set(\wipe, 0.5, \width, 0.1, \trig, 1);
m.free;
 … Since the other post refers to an attachment missing from this thread.
… Since the other post refers to an attachment missing from this thread.
{kind=link}