Say you want to use a UGen to control an external hardware device, independently of the soundcard. At first, one would think that this calculation is time-locked to the control rate, so e.g. at 1.5 kHz for a 48 kHz sample rate and a block size of 32.
But no, of course this calculation is time-locked to the hardware buffer size (I/O buffer size) of the soundcard you happen to use. EDIT: For a typical (low) setting, this is something like 256, so that would be about 190 Hz (5 ms). This may be too much delay for some applications, so we may want a smaller buffer size.
In scsynth, we can set a value for this size via ServerOptions:
// reduce to block size
s.options.hardwareBufferSize = s.options.blockSize;
s.reboot;
Unfortunately, not all soundcards support low block sizes. Also high quality sound cards may have very large ones, actually – this is a cultural thing, when you use them for recording, it is not a problem. But for live I/O it introduces delay (a quarter second is like an eternity then).
So now my question: how do I know if the above setting has been actually successful? How do I know what buffer size is current?
I am sure that on different OSes there are ways to derive this in different ways. Maybe there is a way in supercollider as well?
First off, 1 period / 375 periods per sec is 1/375 sec, not 1/4 sec. A 1/4 second delay needs 12000 samples at 48 kHz.
Then, the hardware buffer size affects the latency with which incoming control messages will be processed (unless they are timestamped). But if a UGen is controlling a hardware device, then it must be by way of the UGen’s output, which maintains full time resolution regardless of hardware buffer size.
Is there perhaps something else unstated about the scenario?
Dahh - of course, that value is completely wrong, I don’t know what I was thinking (correcting it above). In any case, the rate of 375 Hz is too low for the application.
The UGen writes data out to a treadmill, which writes it out to a serial bus of a device. It has no output to the soundcard. Other UGens read from the device. Both happen at a high rate (optimally at 4 kHz).
This is read back from the device after we attempt to set the hardwareBufferSize value from ServerOptions, so this should reflect the actual hardware buffer size. I’m not totally clear on MacOS how this relates to latency, since afaict you can have different audio clients running with different buffer sizes at a given time. My assumption that the observable latency for an audio application is a function of it’s OWN buffer size, and not e.g. the “worst case” buffer size for all applications using that device, but I don’t know the deeper details here.
Supernova uses PortAudio, which has it’s own latency measurements that are posted when the server is launched, but I don’t know how these are calculated:
Latency (in/out): 0.158 / 0.045 sec
But sadly there’s no way to programmatically determine the latency, apart from maybe launching your own scsynth process and scraping the stdout for the above strings…
Yeah I noticed this myself and was a bit confused. Just based on code inspection, we’re pretty transparently passing the value from the CoreAudio callback back as provided by the API, so I don’t know if it’s really possible that we’re munging this here. However, these CA API’s use reference-as-return-value call semantic, which means if they error out they COULD be leaving the variable in an undefined state. I’d have to check, but it might be that this case is simply CA erroring at our obviously bogus request of 1 sample, and then us printing some uninitialized value from memory (which happens to be 15 - because uninitialized values are ALWAYS something confusingly close to what you expected )
This is a guess, I think. Retrying, I get 14! Much better .
But 16 works, so that will be more than fine, at 96 kHz we can get down to 6 kHz if necessary.
Ok, seeing this thread pop up I’m gunna jump in as I have a related issue I’ve been trying to work through for a bit.
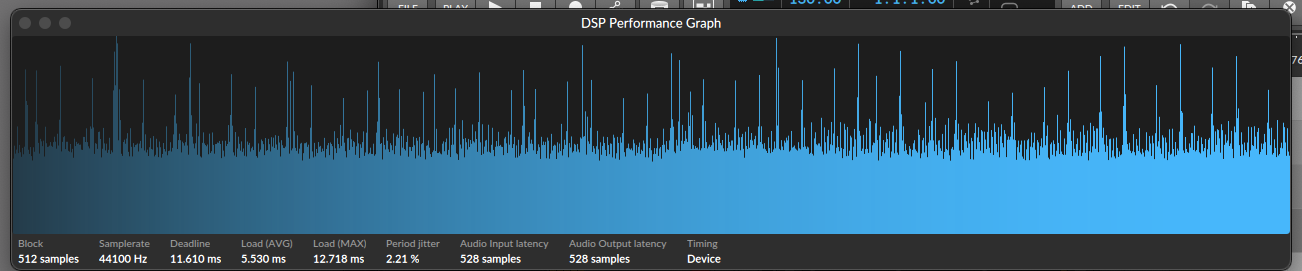
I’m running sc alongside Bitwig Studio. BWS currently set at 512 sample buffer. When both are idle running concurrently I get regular peaks in my cpu usage causing dropouts (see upload). BW on it’s own is fine (although my set is quite heavy). SC on its own doesn’t use much CPU or ran, and this happens just with the server running.
I’m pretty ignorant of what’s going on at a low level, but my thinking there’s a CPU allocation issue where supercollider and bitwig are competing for the same chunk of cpu time which isn’t enough.
To fix this, I have set s.options.hardwareBufferSize = 2048;
With this setting the peaks are still there but lower and I can perform without dropouts. Am I doing something destructive to the signal in by having hardware buffers that don’t match, or am I just adding latency to supercollider?
Checking my parse => the setting refers to sc buffers for the hardware, not my mac’s buffer for the hardware…
This really isn’t ideal, but seems just about manageable for now (I’m processing audio for control not fx).
Is there something I’ve missed or any other config that might be able to ease my issue?
Are you running a bunch of FFT processes? I don’t think it is the hardware buffer size you should worry about. It is the block size. What is that set to? FFT processes, no matter the size of the FFT buffer, need to calculate inside one block size, and that can cause cpu spikes.
If you change the hardware buffer size, does the number of spikes per time change accordingly? That is, for large buffer sizes, are they less pronounced and fewer?
From the point of view of actual calculations: all audio related calculations in scsynth are started at soundcard buffer boundaries.
This means that for large buffers, there is a lot to be done, but can be amortised over the whole period of the buffer, for short buffers, less is to be done, but it has do be completed within a shorter time. My guess is: Because your set is heavy, you can see the effect of the trade off between these two.
The balance may depend on what kind of things are really going on, probably also hardware architecture etc.
Thanks for the clarity. I sort of expect there’s some suboptimal allocation of CPU resources somewhere because overall load isn’t that high, but this is probably beyond my control.
Bitwig does multi-core rendering, which means it will be competing with SuperCollider on at LEAST 1 more (or more if you’re doing multi-core stuff in supernova). In the best possible implementation, the audio subsystem of your OS would schedule these things so that they wouldn’t conflict too much, but if we assume a non-utopia (and if you’re a Windowws user, you’re DEFINITELY not in an audio utopia …) then there might be non-optimal contention.
You MIGHT look for ways that you can reduce the number of cores BitWig is using to prevent contention (I don’t see anything obvious but maybe there are hidden settings if you ask around on forums). No guarantee here but it’s worth experimenting. I can say from experience that changing core utilization for audio processing is something that you can only really tune experimentally, there’s no “right” answer.
Even if it is unclear if it helps, might it be worth a try to use supernova (calling Server.supernova)? This may be competing on more processors, but maybe less intensely on each.
Supernova only parallelizes Nodes inside a ParGroup, though. This means that you have to structure your code accordingly, otherwise there are no benefits.
Coming back here to say that the problem I was having seems to have been somewhere completely different.
I can’t say I know what the original problem was, because the conditions in which I tested it are now yielding a totally different result. However, I can say that now my fix of setting the hardwareBufferSize to 2048 ended up creating a different problem. Having refactored a lot of my code, the original issue, and the need to make adjustments seems to have sorted itself out.
My take away from this is - make sure to set the hardwareBufferSize the same on each program running on the same machine.