I’ve been using OSC with SuperCollider for some time now, but I’m not sure if I’ve ever learned the “correct way”, if such a thing exists. As an example, I’ve adapted this as a possible way of parameterizing - but I’d be curious if anyone has any suggestions for some more robust ways of doing it…
For instance, it would be nice to write the SC functions without all the contingent OSC outputs all nested inside of them, since I might not always want to monitor the OSC.
I also wonder if this is considered an efficient or “fast” way of doing this, since OSC can be a little laggy on its own and I don’t want to make it worse.
One question is, do you need to be sending 1000 messages per second? (0.001.wait)
At least for the LFNoise and envelope in your example, this is waaay more information than you need – and might, I’m not sure, contribute to OSC lag.
Another thought, since each OSC message you are sending is actually three steps (client asks server for bus value, server sends value back to client, and then client forwards value to destination), it would be a little faster to use SendReply, which eliminates one of these steps (see this example from the help file)
// Sending audio parameters over a network via OSC
// Since SendReply can only respond to the host, this shows how
// to send data to a separate target through sclang.
(
SynthDef(\amplitudeAnalysis, {|in=0, rate=60|
var input = SoundIn.ar(in);
var amp = Amplitude.kr(input);
var freq = Pitch.kr(input);
var trig = Impulse.kr(rate);
SendReply.kr(trig, '/analysis', [amp, freq[0], freq[1]]);
}).add;
)
// example target address - insert your target host & port here
~testNetAddr = NetAddr("127.0.0.1", 5000);
~mySynth = Synth(\amplitudeAnalysis);
(
OSCdef(\listener, {|msg|
var data = msg[3..];
data.postln;
~testNetAddr.sendMsg("data", data);
}, '/analysis');
)
~mySynth.set(\rate, 10); // slow it down...
getSynchronous is .kr only. At 48000 kHz and 64 samples per control block, one block = 0.00133333 sec – slower than your poll rate. So some of those polls are guaranteed to get the same value redundantly.
But the redundancy is actually worse than that because getSynchronous can access only one distinct value per hardware buffer. This is because SC calculates all of the control blocks in the hardware buffer at one time. It doesn’t spread out the control blocks over the entire duration of the hardware buffer. If you do getSynchronous at two different times in the middle of the same hardware buffer, you’ll get the same answer because “in the middle of the hardware buffer,” there’s no calculation happening.
c = Bus.control(s, 1);
a = { Out.kr(c, LFDNoise3.kr(200)); Silent.ar(1) }.play;
(
var n = 100;
z = Array(n);
fork {
n.do {
z.add(c.getSynchronous);
0.002.wait;
};
z.postln;
};
)
// note duplicated values
[ 0.32424613833427, 0.32424613833427, -0.18716230988503, -0.18716230988503, -0.18716230988503, -0.23242461681366, -0.23242461681366, -0.23242461681366, -0.42853358387947, -0.42853358387947, -0.42853358387947, -0.78193008899689, -0.78193008899689, -0.78193008899689, ...
]
Decreasing the wait time (increasing the polling frequency) does not improve the data’s time resolution. In my specific case, 256 / 44100 = 0.0058049886621315 so there is no point in polling faster than about 0.006 sec apart. But this is likely to be too fast, depending on what the OSC receiving app is doing. I’d do 0.01 or 0.05.
If you want values from the middle of the hardware buffer, SendReply is the way to go.
getSynchronous uses the server’s shared memory interface and does not send or receive any OSC messages.
I found it quite limiting that the only address to send OSC messages from scsynth/supernova is sclang via SendReply b/c sclang is in the end not too efficient in parsing and forwarding OSC messages (when approaching multiple thousands/sec)
n = NetAddr("127.0.0.1", 50050);
// 10000 msgs per sec
(
f = { |msg|
var raw = msg.asRawOSC;
fork {
loop {
10.do {
n.sendRaw(raw);
};
0.001.wait;
}
}
};
)
a = List.new;
// add a new 10000-msg-per-sec routine
// do this incrementally
a.add(f.value(["/my/sine", 1.0]));
a.do(_.stop);
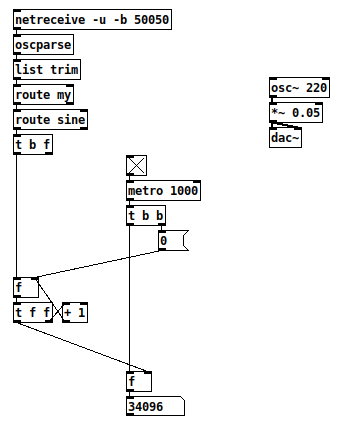
The osc~ is intended to reveal whether a high rate of incoming OSC causes audio dropouts. (It didn’t.) The other part is meant to count how many messages are received per second, but with only one GUI update per second (since rapid GUI updates are known in Pd to cause drop out problems).
Then I added 5 routines, sending 50,000 messages per second. Per htop, sclang is running about 35% CPU at that point (even with sendRaw).
Pd is at about 14% CPU, but it hits a wall at about 46,000 messages per second. Below 46,000, the received count is (approximately) correct. Continuing to add more routines on the SC side doesn’t make a difference – Pd is not processing more than this limit (on my machine – maybe a faster machine would do better – also, I’m on battery power and powersave mode – but tbh I think the UDP layer is the more likely bottleneck).
I also tested with ["/my", 1.0] and found no significant difference – so the two layers of [route] are negligible in terms of performance.
So sending a million messages per second may not be of practical use – good to know that OSCMessenger can send them highly efficiently, but more is not necessarily better
Also it would be worth clarifying here that OSCMessenger is control-rate only.
Documentation says it’s “all notified clients” but I’m not sure exactly how the interactions will work, between maxLogins and server resource allocators.