Hello,
Here (3.11.2):
LPF.ar.isKindOf(PureUGen) == true
LPF.superclass.superclass == PureUGen
Is the use of a random number generator the only way for a UGen to be non-deterministic?
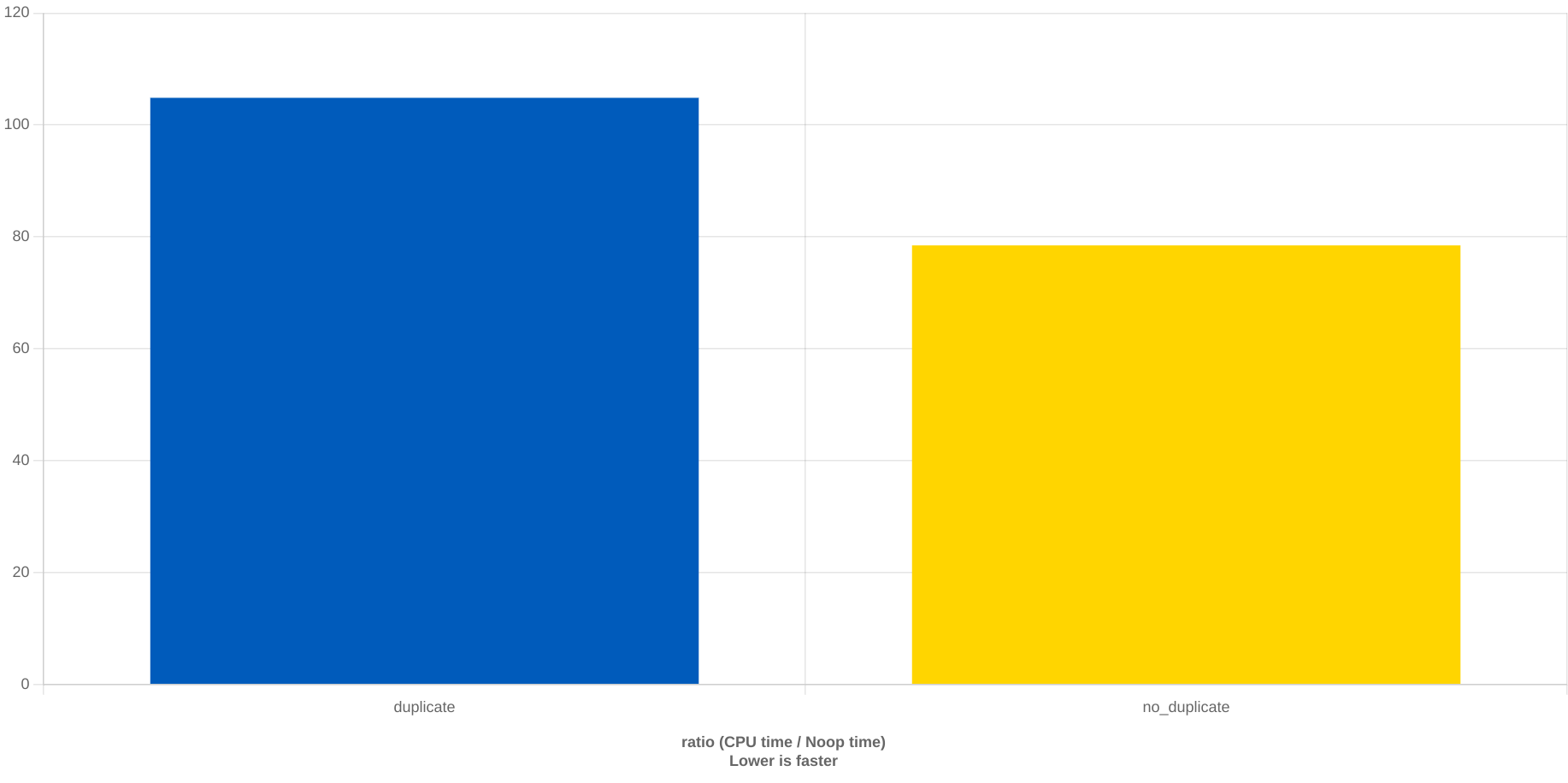
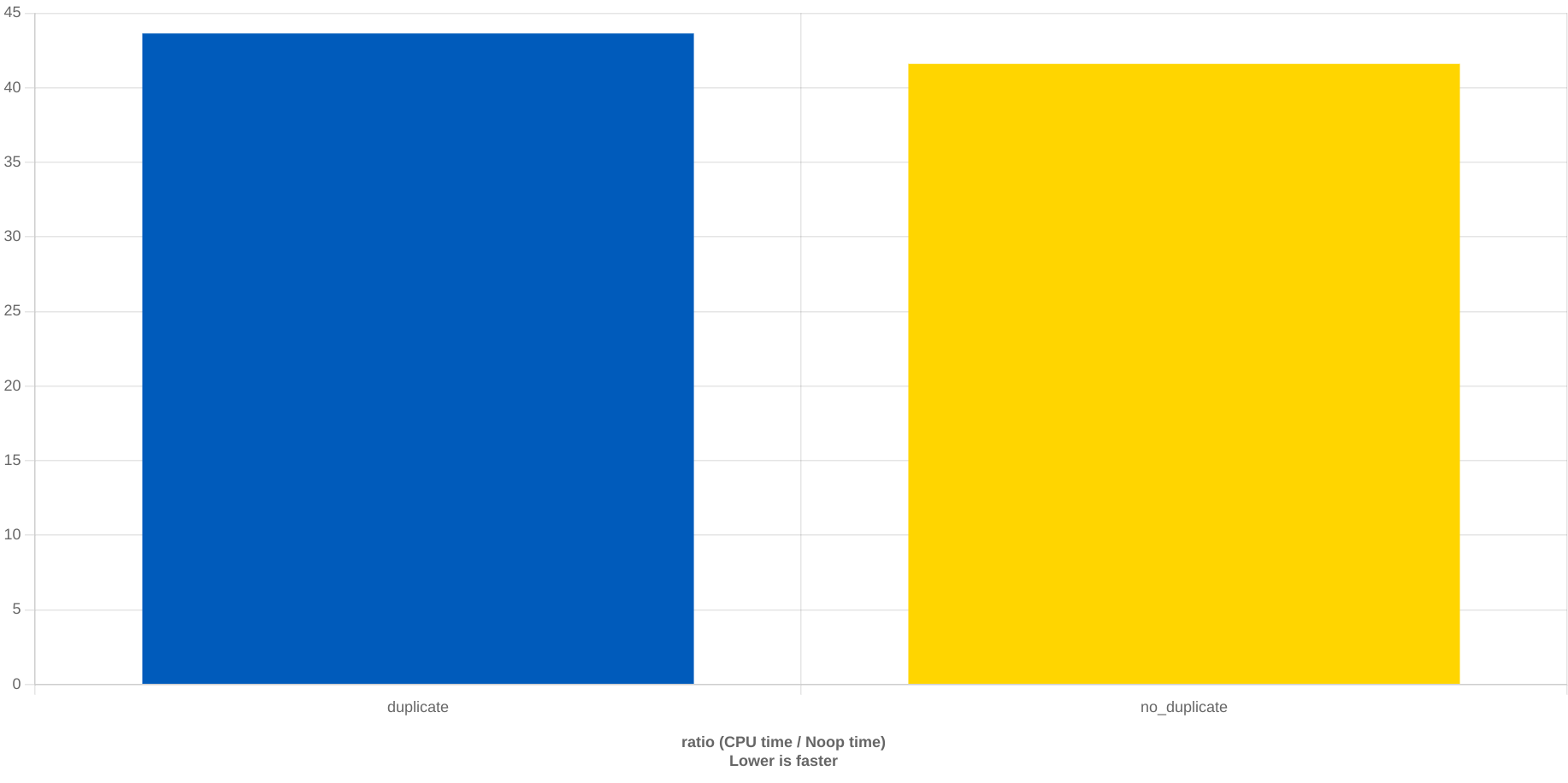
Demand UGens also behave differently if shared, ie.
// Dseq ; shared dseq, different patterns
{var a = Dseq.new(list: [1,3,2,7,8], repeats: inf)
;var t = Impulse.kr(freq: 5, phase: 0)
;var f = Demand.kr(trig: t, reset: 0, demandUGens: [a,a]) * 30 + 340
;SinOsc.ar(freq: f, phase: 0) * 0.1}
// Dseq ; distinct dseq, equal patterns
{var a = Dseq.new(list: [1,3,2,7,8], repeats: inf)
;var b = Dseq.new(list: [1,3,2,7,8], repeats: inf)
;var t = Impulse.kr(freq: 5, phase: 0)
;var f = Demand.kr(trig: t, reset: 0, demandUGens: [a,b]) * 30 + 340
;SinOsc.ar(freq: f, phase: 0) * 0.1}
Best,
Rohan
Ps. Some lists.
Here (3.11.2) the list of UGens marked Pure is:
A2K APF AllpassC AllpassL AllpassN AmpComp AmpCompA BAllPass BBandPass BBandStop BHiPass BHiShelf BLowPass BLowShelf BPF BPZ2 BPeakEQ BRF BRZ2 COsc CombC CombL CombN Decay Decay2 DegreeToKey Delay1 Delay2 DelayC DelayL DelayN DetectIndex DetectSilence FOS Formant Formlet FreeVerb HPF HPZ1 HPZ2 Impulse Index IndexInBetween IndexL Integrator K2A LFCub LFPar LFPulse LFSaw LFTri LPF LPZ1 LPZ2 Lag Lag2 Lag2UD Lag3 Lag3UD LagUD LeakDC LinExp Median MidEQ MoogFF OnePole OneZero Osc OscN RHPF RLPF Ramp Resonz Ringz SOS Select Shaper SinOsc SinOscFB Slew Slope SyncSaw T2A T2K TwoPole TwoZero VOsc VOsc3 VarLag VarSaw Vibrato WrapIndex
(Vibrato is an error, I think. The rateVariation and depthVariation are noise level controls.)
But it’s less work to annotate things the other way about, which I have as:
BrownNoise ClipNoise CoinGate Dbrown Dbufrd Dbufwr Dconst Dgeom Dibrown Diwhite Dpoll Drand Dreset Dseq Dser Dseries Dshuf Dstutter Dswitch Dswitch1 Dunique Dust Dust2 Dwhite Dwrand Dxrand ExpRand Gendy1 Gendy2 Gendy3 GrayNoise IRand LFClipNoise LFDClipNoise LFDNoise0 LFDNoise1 LFDNoise3 LFNoise0 LFNoise1 LFNoise2 LinRand LocalBuf NRand PV_BinScramble PV_RandComb PV_RandWipe PinkNoise Rand TExpRand TIRand TRand TWindex Vibrato WhiteNoise
Which then gives the list of un-annotated Pure UGens as:
Amplitude Balance2 Ball BeatTrack BeatTrack2 BiPanB2 Blip BlockSize BufAllpassC BufAllpassL BufAllpassN BufChannels BufCombC BufCombL BufCombN BufDelayC BufDelayL BufDelayN BufDur BufFrames BufRateScale BufRd BufSampleRate BufSamples BufWr CheckBadValues Clip Compander CompanderD ControlDur ControlRate Convolution Convolution2 Convolution2L Convolution3 Crackle CuspL CuspN DC DecodeB2 DelTapRd DelTapWr Demand DemandEnvGen DiskIn DiskOut Done Duty EnvGen FBSineC FBSineL FBSineN FFT FSinOsc Fold Free FreeSelf FreeSelfWhenDone FreeVerb2 FreqShift GVerb Gate GbmanL GbmanN GrainBuf GrainFM GrainIn GrainSin Hasher HenonC HenonL HenonN Hilbert IEnvGen IFFT In InFeedback InRange InRect InTrig InfoUGenBase KeyState KeyTrack Klang Klank LFGauss LagIn LastValue Latch LatoocarfianC LatoocarfianL LatoocarfianN LeastChange Limiter LinCongC LinCongL LinCongN LinPan2 LinXFade2 Line Linen LocalIn LocalOut Logistic LorenzL Loudness MFCC MantissaMask ModDif MostChange MouseButton MouseX MouseY NodeID Normalizer NumAudioBuses NumBuffers NumControlBuses NumInputBuses NumOutputBuses NumRunningSynths OffsetOut Onsets Out PSinGrain PV_Add PV_BinShift PV_BinWipe PV_BrickWall PV_ConformalMap PV_Conj PV_Copy PV_CopyPhase PV_Diffuser PV_Div PV_HainsworthFoote PV_JensenAndersen PV_LocalMax PV_MagAbove PV_MagBelow PV_MagClip PV_MagDiv PV_MagFreeze PV_MagMul PV_MagNoise PV_MagShift PV_MagSmear PV_MagSquared PV_Max PV_Min PV_Mul PV_PhaseShift PV_PhaseShift270 PV_PhaseShift90 PV_RectComb PV_RectComb2 Pan2 Pan4 PanAz PanB PanB2 PartConv Pause PauseSelf PauseSelfWhenDone Peak PeakFollower Phasor Pitch PitchShift PlayBuf Pluck Poll Pulse PulseCount PulseDivider QuadC QuadL QuadN RadiansPerSample RandID RandSeed RecordBuf ReplaceOut Rotate2 RunningMax RunningMin RunningSum SampleDur SampleRate Sanitize Saw Schmidt SendTrig SetResetFF SpecCentroid SpecFlatness SpecPcile Spring StandardL StandardN Stepper StereoConvolution2L SubsampleOffset Sum3 Sum4 Sweep TBall TDelay TDuty TGrains Timer ToggleFF Trig Trig1 VDiskIn Warp1 Wrap XFade2 XLine XOut ZeroCrossing MaxLocalBufs MulAdd SetBuf