{Rand(0.5,8)}
{rand(0.5,8)}
Is there difference ??
{Rand(0.5,8)}
{rand(0.5,8)}
Is there difference ??
I think you meant to compare Rand and rrand (not rand) – both generate a random number between a given low and high, but Rand is intended to be used inside a SynthDef and the behavior is slightly different. Compare:
(
SynthDef(\test, {
var freq = rrand(400, 600);
Out.ar(0, SinOsc.ar(freq) * 0.2);
}).add;
)
Synth(\test); // run and stop multiple times: always same freq
(
SynthDef(\test2, {
var freq = Rand(400, 600);
Out.ar(0, SinOsc.ar(freq) * 0.2);
}).add;
)
Synth(\test2); // run and stop multiple times: every time a different freq
As you can read in the help file, Rand is intended to be used inside SynthDefs when you want the particular behavior of a newly generated random frequency for each Synth called. You can use rrand(lo, hi) inside a SynthDef too, if you want the random number to be generated only once at time of SynthDef creation (it gets “inscribed in the recipe” for good), so all future and all Synth calls based on that SynthDef to use on that same random number.
As a side note, rand (as opposed to rrand) generates a random number between zero and the receiver:
rand(8); // random numbers between 0 and and 8 (excluding 8)
rand(0.5, 8); // random numbers between 0 and 0.5; second argument is ignored here
Also in regards to the specific way you present the example (as Functions, indicated by the curly braces): note the difference when you evaluate them:
{Rand(0.5,8)}.value; // returns 'a Rand'
{rrand(0.5,8)}.value; // returns an actual random choice between lo and hi
Hope this helps,
B
oh,thank you,detail.
it became ,clear.
thanks again.
this is perpetual source of confusion which suggests that it’s not the best design!
I wonder if there are some quick and dirty improvements that might help? Rrand.ir(3,5) ?
or a warning if rand(3) is encountered in a synthdef?
I also think that it would probably have been better to decide for something like Rand.ir – e.g. for RandID this is the case.
I suppose this is not feasible, any language operation is valid in a SynthDef and this is a powerful construction concept, though, admittedly, an endless source of confusion.
One thing that might help clear up the confusion is to make the documentation more explicit that everything happens in SC by way of a method. And, all method calls have a receiver, a method selector, and optional arguments.
rrand(3, 5)
Rand(3, 5)
So they are not analogous at all. Rand(3, 5) is syntactically closer to Point(3, 5) than it is to rrand.
Unfortunately I think there’s no way to remove this issue completely. Just as in learning a human language, grammar is highly abstract and the implications of syntax rules aren’t well understood until you’ve made a lot of mistakes. Even if the intro tutorials hammered harder at this, it’s totally normal for the distinction between class and selector to be fuzzy until hitting a case where one’s mental construct didn’t work.
It would be possible to deprecate Rand.new in favor of Rand.ir – the latter is also semantically more accurate. It probably should have been that from the start.
A “SynthDef check” would slow the performance of all rrand calls everywhere. Also there are cases where it’s valid to use rrand in a SynthDef, so I wouldn’t be in favor of this approach.
hjh
while we’re here its hard to see why there is both a rrand and rand method!
why not a single method rand that takes an optional argument? so that 3.rand would be as now while 3.rand(5) would replace rrand(3,5) ?
In an ideal world you would be able to wrap these calls on numbers in a function and call .ir like {5.gaussian}.ir to get an evaluation at initialztion time…
Then the receiver’s meaning would change based on the presence or absence of an argument. With the proposed semantic:
rand(3): receiver 3 is the upper bound;rand(3, 5): receiver 3 is the lower bound.I’m not sure which is less objectionable: two methods with closely related functionality, or one method where the meaning of the inputs changes based on context. (I don’t mean that as a rhetorical device – I’m genuinely not certain which is better/worse. If SC had template-matching method dispatch [I’ve probably used an incorrect term for it], there would be a strong argument for the single method name and multiple argument signatures. But we don’t have that, so we could also say it’s not idiomatic for a language where dispatch is entirely based on the receiver.)
hjh
In general, highly conditional behaviors based on argument values is usually considered an anti-pattern.
There is some grey area here for SuperCollider, because sclang puts a priority on expressiveness - this sometimes means prioritizing polymorphism, and designing API’s with the user intention in mind over predictability. Nonetheless: IMO cases like core library functions, rand or rrand, fall firmly on the side of predictability.
Sclang is very easily to extend: writing hyper-flexible “utility” versions of something like random number generation is best done in a Quark or a local class extension. I have lots and lots of local extensions that serve this exact purpose.
my thought was that there would be an implicit 0 argument. So 3.rand would be 3.rand(0) which is the current situation…
And then Rand could have the same implicit 0 second arg allowing Rand(3) …
I didn’t think this would work… Random number generators typically don’t handle an inverted range.

Side note: Even if the random number generator can’t invert, it can still handle a negative lower bound, provided that it really is the lower bound: 50 - (-20) = 70, “random 70” works, then + (-20) gets it to the desired range.
But JMc is “smarter than the average bear” and made the random number functions work with reversed bounds:
10.do { -10.rand.postln };
-3
-3
-10
-4
-8
-1
-7
-4
-10
-10
So rrand(3.0, 0.0) calculates as -3.0.rand + 3.0 and it’s all good.
So that would actually work (but be careful if you try it in other languages). Edit: Changing it now would break argument defaults though.
hjh
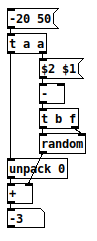
PS In Pd you could implement a smarter rrand like this:
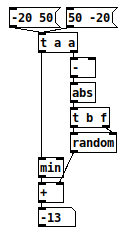
Haskell being a fascinating exception ![]()
Edit: In SC, currently we have constant-time method lookup. Haskell-style dispatch based on argument types or values would make this O(> 1) and that would be very bad for interpreter speed (which is slow enough) – so I would advocate against that. Still, it’s fun to speculate what it would be like to be able to write d’après Haskell “rand(number): xxx; rand(number, number): yyy” – if it could be performant, it’s kinda cool (but I don’t see how to make it performant with SC’s interpreter design).
Further edit: I’ve just been looking a bit into Open Frameworks and there, it seems common to overload functions for different numbers of arguments, e.g. getColor(index) vs getColor(x, y) – so I’m not sure if it can really be said that this is an anti-pattern after all.
hjh