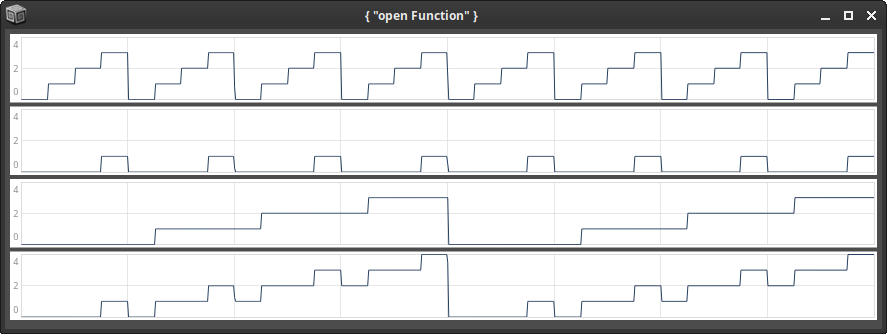
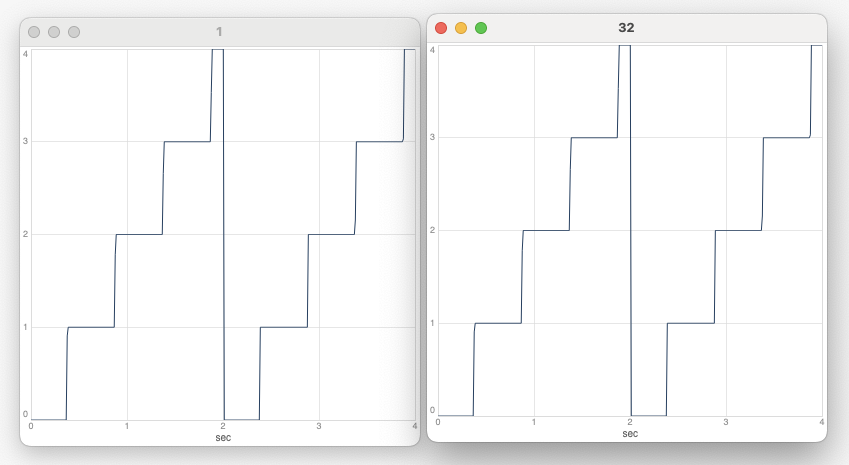
Hey there,
I’m noticing some very strange behaviour (or missing something?): The following piece of code behaves differently on my two Mac Computers:
(
var blockSize = 32; // = 1 works on Intel, 32 doesn't
var tempo = 120/60;
var hexStep = { |chars, div=4|
var phase = Phasor.ar(1, tempo/SampleRate.ir, 0, 4);
var c = 0;
var table = (0..15).collect(_.asBinaryDigits).collect(_[4..7]);
var seq = chars.asString.asList
.collect{|char| table.at( ("0x"++char).interpret) }.flatten
.collect{|bool| c = c + bool };
var length, step, repetitions, trig, index, rawStep;
phase = phase * div;
repetitions = (phase.trunc/seq.size).trunc;
index = (phase).mod(seq.size).floor;
rawStep = Select.ar(index, K2A.ar(seq));
step = rawStep + (repetitions * seq.last);
trig = Changed.ar(step);
step
};
s.options.blockSize_(blockSize);
s.waitForBoot({
{ hexStep.('1', 4) }.plot(4);
5.wait; s.quit;
});
)
When I run this on my 2012 MacBookPro, SC 3.14.1, MacOS 13.7.4, I get this (incorrect) output:
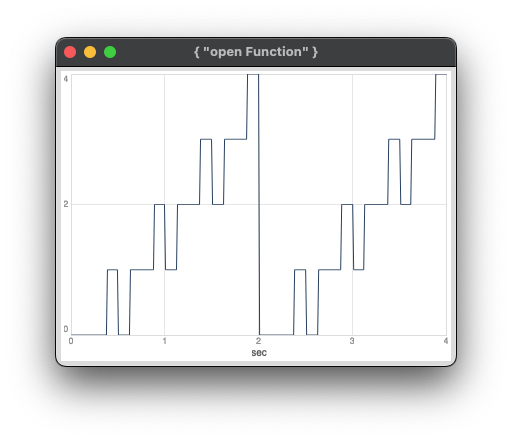
When I change the blockSize to 1 on the same machine, I get this (correct) plot:
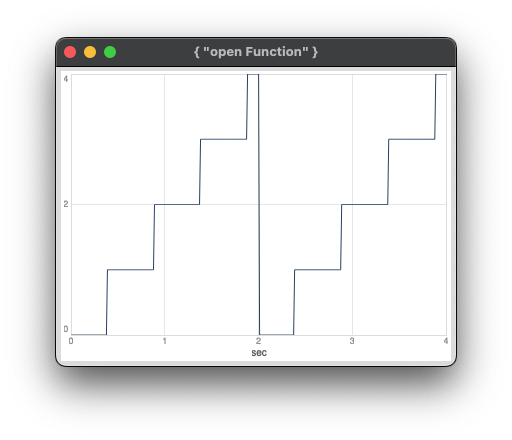
However I cannot recreate the behaviour on my newer M2 machine (also 3.14.1, Mac OS 14.4.1). I always get the correct plot #2, no matter the blockSize. Samplerate was 48k, hardwareBufferSize 512 in all tests.
I also ran the same example on a Mac OS10.13 Intel machine with SC 3.13, which had the same behaviour as the other Intel Mac.
Does anybody know what could be going on? I have struggled quite a lot with getting the Select.ar-lookup right and preventing the jumping output on the first plot and can’t wrap my head around why this should have anything to do with the blockSize in the first place. Any hints would be greatly appreciated! ![]()
All best and thank you for reading this lengthy post!
moritz