IMO, this is exactly how I feel about SC4.
I see tomorrow’s SC as a refined & pristine (everything *just works*) and deployable version of SC, i.e. *for* every platform.
Perhaps separate from, or as a (premium?) extension of SC3.
IMO, this is exactly how I feel about SC4.
I see tomorrow’s SC as a refined & pristine (everything *just works*) and deployable version of SC, i.e. *for* every platform.
Perhaps separate from, or as a (premium?) extension of SC3.
I found this old article interesting:
https://jonathanwhiting.com/writing/blog/games_in_c/
Smalltalk and so also SC(?) seems to ask for a stricly object oriented way of working. The consequence seems to be that I find myself constantly working through the helpfiles. This can kill creativity.
I mean he’s really asking for Rust. Data orientated, no GC and strong tooling.
If I was redoing SuperCollider today I’d ditch the IDE (VSCode is really good for people who want something that just works, and the Atom interface seems basically identical in my experience) and the language. Language design is hard, time consuming and nobody can agree on what they want (personally I like strongly typed functional languages and hate OOP). SCLang is never going to have feature parity with Python/Ruby/pick your poison - because nobody has time for that.
I’d also rewrite the server in Rust - but I realize that’s a controversial opinion 
I like IMGui - but I’m not sure it’s the best solution for a GUI that handles all logic through OSC messages.
I’ve contemplated whether SC4 should have a more stripped down version of the core library, and rely more heavily upon the Quarks interface, for extended functionality.
I was an advocate for that but the problem was backgruard compatibility, which is really a problem. Another idea was to make the components that make up the entire SC package much more modular and not dependent on each other. Borrowing your word, a pristine scsynth, supernova, sclang, scide. Lately I was thinking what if scsynth was a lean C/C++ application/library embeddable in other ecosystems, as a modular dynamic runtime based on server commands (always GPL) whatever the language. In any way, it is quite a work to do.
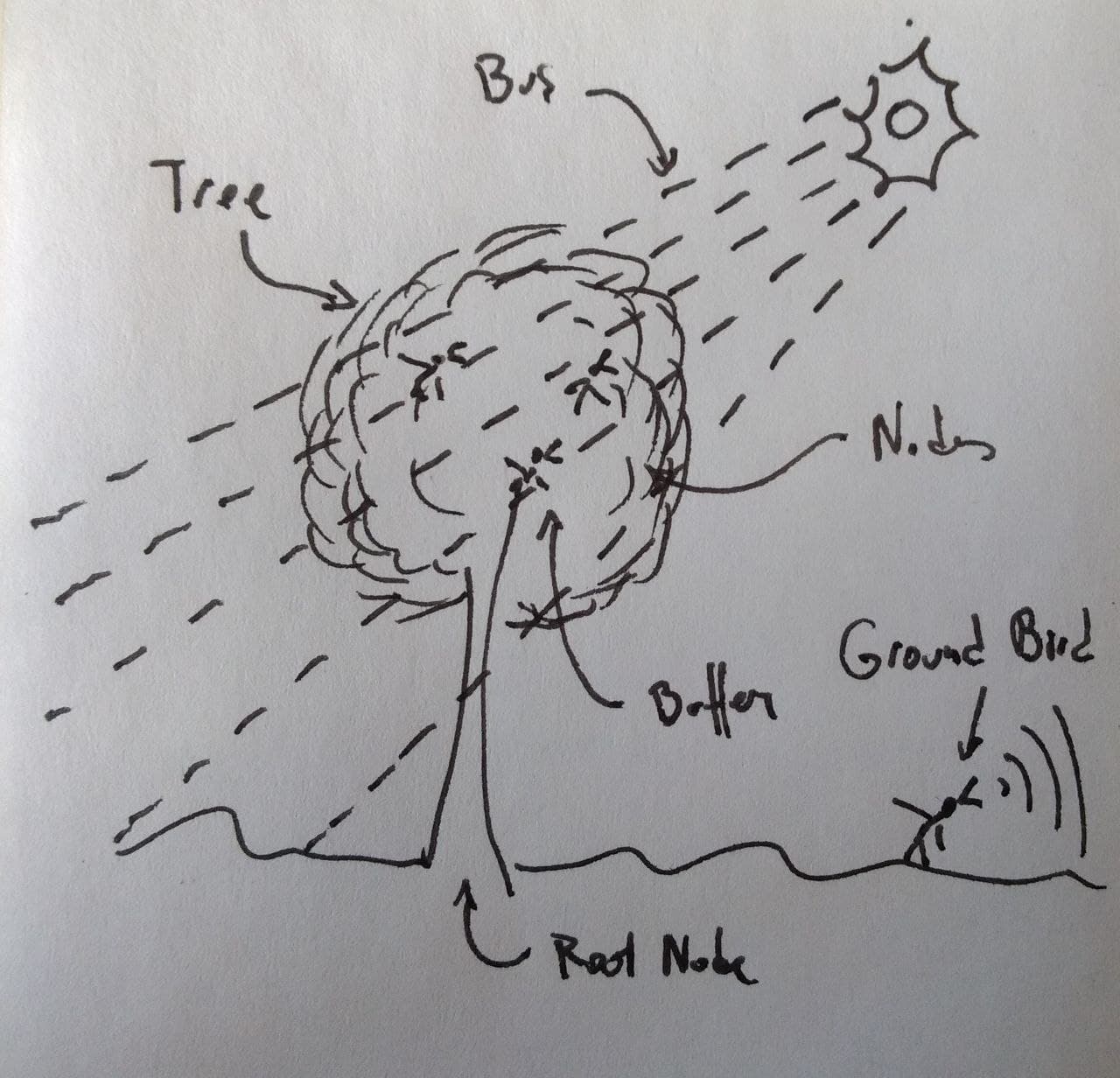
Mostly because I think that the original server design, as a tree with global buses, is a very simple and elegant solution proven to be very flexible.
I’ve made schematic representation:
Lately I was thinking what if scsynth was a lean C/C++ application/library embeddable in other ecosystems, as a modular dynamic runtime based on server commands (always GPL) whatever the language.
Actually, that is already possible. scsynth can be built as a shared or static library (libscsynth) and then embedded into programs. It has a pure C interface that you can find in include/server/SC_WorldOptions.h.
scsynth uses no global state, so you can have as many independent instances as you want. That’s why projects like SupercolliderAU (= scsynth as an AU plugin) are possible. Supernova, on the other hand, is really is a singleton application; you can embed it, but you can only ever have a single instance.
The only thing that libscsynth is lacking IMO is a generic plugin audio driver. Currently, it still uses the usual audio backends (CoreAudio, portaudio, jack), so when you start an scsynth instance, it would open an audio stream under the hood. However, many applications already use their own audio backend, so what we really want is a simple function to send audio data to scsynth as input and receive audio data as output, similar to how audio plugins work.
This is how libpd actually works: it’s Pd but without the audio backend code removed. Instead you get a function like this libpd/libpd_wrapper/z_libpd.h at 9b704321a7b0bca087c9f6f888aa4a1fa0030fd4 · libpd/libpd · GitHub that you can call in the audio callback.
So in theory you could have another instance of SuperCollider as a Ugen. That might be an interesting way to prototype DSP stuff, as you could run that UGen at a buffer size of 1, and even (in theory) have it at a different sample rate.
Yes, I already had this idea. Reblocking and resampling would definitely be possible.
It would even allow multi-threading / multi-processing in scsynth because you could run the sub-instance in a seperate thread or process with a double buffer or ring buffer, similarly to the [pd~] Pd object. However, that wouldn’t make so much sense since we already have Supernova.
Is it theoretically possible for a future version of SC to include only the core server & client architecture, along with a bare steel internal package manager (integrated with git & networking) serving as the Quarks/extension interface?
And as a comprise to resolve the problem of “backwards compatibility”, if one attempts to run a script which contains class names that are not found in the local source, then (perhaps) the interpreter would use git to check for a dedicated directory file (a table of package names for keys which are then bound to arrays of class names installed by the package) and would then, in the case of such an event, print something useful such as the code that would need to be run in order to download any/all necessary packages not found in the local source?
And would something like this ruin the prospect of having the future SC exist with comparable performance to being able to run Pd headless on an SP32 w/ only 512 kB of RAM?
If you’ve used Pure Data (as I do in the classroom) then you already know what this is like: 1/ features that you thought were core might not be (e.g., in Pd, signal rate comparators are external ![]() … so it’s not
… so it’s not sig > 0.5, it’s ((sig - 0.5) * 1e34).clip(0, 1) – I’m afraid I’m not joking about that, without cyclone that is really what you have to do) and 2/ because extras aren’t mentioned in the core documentation, the only way to find the right extension is to ask on the user forum and wait for someone to answer. To Pd’s credit, with deken, they have made externals even easier to install than SC.
There may be good reasons to go that way, but it’s no utopia.
hjh
In the endeavor of envisioning such a utopia, I wonder if we could make the first level an advancement from where typical usage starts at the second.
By comparison, with Pure Data, one is essentially cornered into Pd-Vanilla… Pd-Extended has been abandoned for nearly a decade.
The level of performance Pd achieves on microprocessors with limited resources is a considerably advanced feature, though it is standard to it’s core distribution.
I propose that we may achieve the same level of versatility, while remaining accessible to one’s first impression.
If SC4 can effectively achieve the raw deployability of Pure Data, the compatibility with as many platforms as Faust, while earning a reputation as the premiere & open-source solution for interfacing OSC communications between any and all platforms & applications ( a central control hub that makes OSC routing between apps a robust simplicity )
…if utopia may be achieved, then I see no purpose in driving towards a vision of anything different, for SC.
That’s just a problem with languages that don’t support proper modules with namespaces.
Actually, Pd does have some kind of namespaces: you can prepend the library path, e.g. [cyclone/zl]. However, it’s entirely optional and many users are too lazy to type those extra characters, so you end up with the very problems you’re describing.
Sclang, on the other hand, just drops all classes in the global namespace. A very common solution is to prepend every struct/function with a library prefix. Unfortunately, this is up to the library author and can’t be enforced at the language level…
(e.g., in Pd, signal rate comparators are external
This has always been a pet peeve of mine. There really is no convincing reason why signal comparison operators are not part of Pd vanilla. The only explanation is that Miller just forget about it and nobody cared enough to make a PR - including myself. I’ve just opened an issue (https://github.com/pure-data/pure-data/issues/1449) so I don’t forget ![]()
the only way to find the right extension is to ask on the user forum and wait for someone to answer.
In Deken you can also search for individual objects and it will show you the library/libraries. There even is a website: http://deken.puredata.info/. Unfortunately, it doesn’t work with objects containing “forbidden” characters, like [>~], [<~] or [||~] (unless the author provided an object list).
To Pd’s credit, with deken, they have made externals even easier to install than SC.
I also think that Deken is a nice package manager. One thing I am missing is a list of all available externals, like you get with Quarks.gui. Ideally you would also show the download stats, so people can sort the list by popularity.
EDIT: you can get a list of all available externals by doing an empty search. But the resulting list is a bit unwieldy
I think I could see scserver and sclang being two separate packages/installs. Scserver and sclang would still have to be “official” though. I just can’t see how releasing SuperCollider without a Patterns library or JitLib, for example, could be a solution to anything.
To clarify, the implication was that there would be a bare steel version of a future release of SC, which would contain:
…and not much else, as a way to achieve the raw deployability that is a trademark of Pd.
It would be available as a more advanced feature, for anyone who wanted their own custom or headless SC to run on a downsized system.
Food for thoughts
Well, if you add a name mangler that sortof imitates what linker does, then it actually is useable, for me. Otherwise you can’t include the same function more than once in the same sythdef, if it has any control args of its own. Name conflicts are horribly handled right now, by the standard SC machinery, but at lest for func args there a is straighforward fix to make them visible across lexical units. The dynamically generated names by the old Control.names interface have rather horrible corner cases that I personally didn’t find worhtwhile supporting, rather than patching the few places in JITLib where they were still used for some reason (There also use of the NamedControls in nearly the same library, e.g. in GraphBuilder.)
Hers’s another feature to ponder: names for control busses, and perhaps for all busses.
Inside a single SynthDef you can give your controls, connecting wires and in fact all your signals, meaningful names (which pretend to be variables), at least during Synth development, except for outputs.
So a logic control synth has decent names as input and just a largish array as output. I can’t think of any EDA package or circuit (HDL) language (e.g. Verilog) from the last 40 years that was like this, where inputs in your circuit can be named, but outputs cannot.
Yeah, I’m probably going to get one of those “I’ve been using SC for 20 years and never needed this” replies or “this is music/dsp software, not circuit design, so we’re used to bus numbers because we only use a handful”.
By the way, CSound added a signal flow graph facility around 2010. And it has multiple names outputs, much a like a HDL. But it falls short of SC’s flexibility because CSound uses a syntactically specified graph, as far as I can tell, whereas in SC the graph is obtained by some OOP magic by running the user’s SynthDef function on some special objects (OutputProxies) passed as inputs. (Really, it’s the simplest way to use OOP to generate an abstract syntax tree. It was like assignment #2 in a compiler class I took 25 years ago, or so.)
Perhaps in keeping with CSound philosophy, one is expected to run an external program to generate a graph from an OOP-like paradigm, as for CScound scores in general there are (too) numerous external generators, CMask and what not. There’s some discussion on their dev list on philosophical differences in that regard, where it was even noted that “one can not define [a] Reverb instrument and use multiple instances of it with the inlet/outlet/connect [CSound] opcodes. In a system like SuperCollider, one might instantiate multiple Synth instances of SynthDefs but tell them which channels of the bus to read from/write to, and that’s done at the instance level, not the definition.” Well, if you use my fairly simple SC mangler extension, you can easily have multiple function instances compiled in the same SynthDef (without control name conflicts), so you can even have it as one SynthDef in SC.
Another thing that could perhaps be done as a UGen: some kind of address decoder, so if you have e.g. 128 synths you don’t need 128 * number of params busses to map them to some control logic. But you can have them select themselves based on an address bus (only 7-bit wide in this case) and have them only read from the data bus (the only needs to be as wide as the params) when their in-built address matches what’s on the address bus. If this sounds too “circuity” for music, just think how MIDI works: it doesn’t use hundreds of wires for interconnect, which would happen if you had one wire per instrument to select them.
Pause.kr can do a wee bit of this as it’s the only UGen I know that can do something to another based on its id. But it’s flexible enough, because it can just turn some other node on or off.
I actually overestimated how difficult is to do this part in current SC, when I wrote the above. It turns out it’s actually fairly easy… because SC busses pass floats, not just bits… duh.
I am not sure if this was mentioned (probably yes), but a more homogeneous syntax would be a good fix point, as discussed here.
type conversion is working under heterogeneous methods:
("some"++"string").asArray; // -> somestring
("some"++"string").asArray.class; // -> String
("some"++"string").as(Array); // -> [ s, o, m, e, s, t, r, i, n, g ]
("some"++"string").as(Array).class; // -> Array
Moreover:
1.asInteger.class //returns Integer
1.0.asInteger.class //returns Integer
[1.0, 1.0].asInteger // returns an array of Integers
-> [ 1, 1 ]
1.0.as(Integer); // ERROR: Message 'newFrom' not understood.
1.as(Float); // ERROR: Message 'newFrom' not understood.
\a.as(Char); // ERROR: Message 'newFrom' not understood.
However:
[1.0, 2.0].asInteger // -> [ 1, 2 ]
$a.asInteger // -> 97
"a".asInteger // -> 0
[$a, $b].asInteger // ERROR: Message 'asInteger' not understood.
This is really confusing for those beginning with SC and I guess it is incovenient/troublesome for advanced users.
A similiar problem is related to OOP capabilities of the base classes. Array2D for instance is capable of responding to a admittedly small amount of methods when compared to Array. Why having Array2D at all in this small implementation if most users are creating 2D array by nesting Array due to the lack of methods ? Thinking in the begginers usage, I guess many people have spend some time trying to use Array2D until they realize this and went back to nested Array. IMO this is steeping the learning curve…
Moreover Array2D syntax seems to be too close to the syntax of arrays of arrays. In the case of the keeping this class on SC4, wouldn’t it make more sense to have an alternative syntax ? eg. [1 2 3; 4 5 6; 7 8 9] ?