I hope to contributed some documentation improvements (too). I see I can open the help files as source inside scide too (although the syntax highlight on the non-code text looks a bit wonky, e.g. capitalized words are highlighted as class names). But how do I recompile just one help file I changed? Recompiling the whole help tree is pretty expensive as time (even more so than compiling the class library!)
Syntax highlighting: I edit in atom and it has the opposite behavior, i.e. everything highlighted properly except code
Then there is this, in case you haven’t seen it: https://supercollider.github.io/contributing/ideconfig-contrib
I dont’t know how to recompile only one file, I usually recompile the whole sc 
I’ll take this occasion to research it and improve my workflow along with you 
EDIT: I’ve found this
SCDoc.parseAndRender(SCDoc.documents["Classes/EnvGen"])
But anyway, everytime I edit a source .schelp, when I reload that page in scide’s help browser, a re-index is triggered. So, it’s faster to open that compiled help file in a browser and reload it from there
SCDoc.documents["Classes/EnvGen"].destPath.openOS
I don’t think it would be hard (last famous words) to make a script that watches your helpSource and recompiles changed files!
I did a little script here, that needs testing! The idea is to have this watcher automatically rebuilding only changed files, and reloading your browser’s tab when you want to see changes.
I opt for browser instead of scide to avoid re-indexing all the time, can be for sure improved to figure out when re-indexing is actually needed.
1 Like
Yeah, I figured I can make a “private” copy of a help file I’m working on if I put it in my extensions folder (in an appropriate HelpSource sub-folder thereof). It does show up alongside the “regular” one but with a [+] next to it (because it’s from an extension)
But full-index rebuild every time I hit reload on the file in the scide help browser is a bit of bummer.
(There’s also the issue that tabs don’t render to the same number of spaces in scide and the help browser, with the default settings for both.)
So far the only way I found to avoid re-indexing is indeed looking at the file in another web-browser, and reloading from there.
If you are fine with that, maybe you’ll like my script
I was stumbling upon this a while ago. I think I wrote a few lines using
SCDocHTMLRenderer
to render all files in a subfolder of the Extensions folder, can’t find it at the moment.
1 Like
On a release build of scide, indexing the entire help source takes about half a second, I am fine with that delay when I edit help documents.
it’s true, the IDE doesn’t have syntax highlighting for scdoc syntax. scvim does though (i added it ).
It may be worth looking into whether the entire index needs to be recreated from scratch every time a single file changes. I bet there is some optimization that can be done there, despite the complications of inter-document dependencies and references. at the very least we can probably get by without re-parsing files that haven’t changed.
On a Mac maybe. On Windows it’s 5 secs for me in Win 7 and 20 secs in Win10, on the same machine (SSD + 12GB RAM.) I’ll try an Ubuntu install later, but I’m not expecting miracles.
Classlib recompiles are only 1 second in Win 7 for me on the same machines. So definitely something odd with help builds in comparison (there can’t be that many more help files than class files, and the process is doubtfully more CPU intensive to parse the help and put out some html.)
Actually, there are about twice as many, but still not 4-5 times
SCDoc: Indexed 2362 documents in 5.32 seconds
[classlib] compiled 1026 files in 1.26 seconds
This is with a few extra libraries installed. I think the blowup is because several classes can share a file, but each class gets its own help file. So even if some are undocumented…
FS caching in Ubuntu is fine.
// first time, without schelp files in FS cache
SCDoc: Indexing help-files...
SCDoc: Indexed 3276 documents in 11.76 seconds
// second time, immediately after
SCDoc: Indexing help-files...
SCDoc: Indexed 3276 documents in 1.94 seconds
When it’s slow, the bulk of the time is disk access. I think you’d mentioned your system specs before; I’d be very surprised if it’s a CPU problem.
the process is doubtlessly more CPU intensive to parse the help and put out some html
Indexing help files and rendering are different things. Indexing should parse only the preamble and not render HTML for every help file (rendering is on demand).
I fully understand how frustrating it is that these basic operations are so slow on your system. But I think it would be good to start strategizing what could reasonably be done about it. To be completely honest, I think the most productive way to start is to investigate any configuration options on your system that could speed up file access, or get FS caching to work better. It seems pretty clear to me that the problem is Microsoft’s fault.
The only thing I could imagine in SC is to reduce file system access – but, how? That’s the cruncher… If SC kept file contents, or parts of contents, in memory, it would improve your case but also take SC developer hours to re-architect an alternative to a feature that is supposed to be provided by the operating system.
It may be possible to speed up the case of reindexing help files, when the index already exists in sclang interpreter memory (i.e., no library recompile since the last index) and only one or two files have changed – if part of the index is the file’s File.mtime(path) (it isn’t currently, I’m pretty sure), then we could check for files that have been modified and simply not open the unchanged ones. (But, if Windows responds slowly to File.mtime as well, then there may not be much benefit – we just don’t know.)
Class files are read en masse only during library compilation, so there is nothing that could be retained in SC interpreter space. Retaining class source code in sclang process memory, while technically possible, would effectively be to reinvent file caching. So I’m afraid that’s probably a nonstarter.
hjh
Caching per se is not the issue. It’s the fact that there are thousands of files, even if they total only a few MB (true for help and the classlib). If you look at some FS talks, they have scaling issues with stuff like this and FS APIs are full of (OS-specific) gotchas.
Or https://www.python.org/dev/peps/pep-0471/ Python improved their directory scan perf on Win by about an order of magnitude by not doing some redundant ops. It’s much more likely it’s some gotcha like that.
If I do (from win 7 cmd prompt) in the HelpSource tree
findstr /sinp "blubb" *.schelp
It returns almost instantaneously. That’s with a string that’s not found, so there’s no terminal IO at all. (And yeah, the command does really recursively grep all the files, I tried with some strings that are found in the help files.)
Measure-Command {findstr /snip "blubb" *.schelp}
TotalSeconds : 0.2281333
TotalMilliseconds : 228.1333
So there’s not a real caching issue, but much more likely some issue with an API that SC is “using it wrong” on Windows.
So there’s not a real caching issue, but much more likely some issue with an API that SC is “using it wrong” on Windows.
that’s also possible. on Linux, strace is a way of tracing calls to kernel syscalls including their arguments. if there is an equivalent on Windows, running it during this might lead to some insights.
My suspicion right now narrows to either some kind of bad-delete behavior for the old html files (getting delete done properly on Windows is apparently tricky, per the talk I linked / mentioned earlier) or to some kind of sync write problem for the new files. I’ll have to hone my Windows profiling skills to figure out more… I still have a mechanical HDD around, I could try to “debug by ear” if it’s a sync write issue…
Indexing calls prParseFile on each file (I had hoped this would stop after the preamble, but it seems that it does parse all of the contents, so that could be a performance drag – but it’s still reasonably quick on my system, when FS cache is being hit). It doesn’t invoke SCDocHTMLRenderer. Indexing is read-only (or should be – if you find that it isn’t, then that’s a bug).
hjh
Some of my Win 10 problems were almost certainly some MS bug (possibly in their malware scanner). After doing literally nothing (in Win 10) but rebooting it once a week to pick up updates… classlib compile times in SC 3.11.0 are now amazing, faster than in Win 7
first run
compiled 866 files in 2.03 seconds
recompile
compiled 866 files in 0.91 seconds
However class tree init is still slower than in Win 7 (it was under a sec there)
Class tree inited in 1.74 seconds
And help files compile are still a lot slower in Win 10 (about 4 times slower than in Win 7):
SCDoc: Indexed 2050 documents in 16.94 seconds
but only the 1st run! On a 2nd run
SCDoc: Indexed 2050 documents in 3.16 seconds
beats win 7 (albeit somewhat fewer files). So, yeah, I think MS mostly solved whatever issue they had with SC with the weekly updates…
There’s something still very weird about Windows and help though. Installing SC 3.10.0 (comes in the repo) on Lubuntu 20 in VMWare on the Win 7 host… resulted in this on a first run:
SCDoc: Indexed 1349 documents in 1.18 seconds
That’s in a VM on the physical machine! So just on “cold” startup the Linux/VM is faster than the native Windows app in any circumstances! (even if you multiply that time by 2 to account for the file count differences–had no quarks installed.) The start-up classlib compilation in VM wasn’t so amazing, but still decent
compiled 318 files in 1.96 seconds
Actually, the documentation is pretty broken on Lubuntu, so the timing above is rather irrelevant. The code examples don’t show at all, only the “regular” text does!! And even the methods index is broken… Thankfully that’s only the case with Canonical-shipped 3.10.0. With tree compiled from the develop, the documentation works fine, examples included. And even after rebooting the VM I get
SCDoc: Indexed 1450 documents in 1.8 seconds
on a develop-SC start. So the sluggishness in help building on Windows (10) on a first start is still quite baffling…
Also, while VM can produce sounds e.g. with Firefox on youtube, the SC server “plays” completely silent, albeit with no errors shown of any kind… Actually, I’ve managed to fix that. Totally obscure VMWare thing: apparently if you let Jackd connect to the inputs, you get no outputs (but no errors)! So you have to go in the qjackctl control panel and select “playback only”.
1 Like
Besides what probably just MS anti-vir stuff, there rest is “NTFS stuff”
Basically, the TLDR version is that closing files you’re written to is much slower on Windows/NTFS because of their device model. It’s a sort-of built-in “sync” that can’t be avoided unless you spawn a thread pool that does just file handle closes. The Windows AV is actually part of this problem because it’s implemented as a filter driver that won’t let you close a file if fails the virus check!
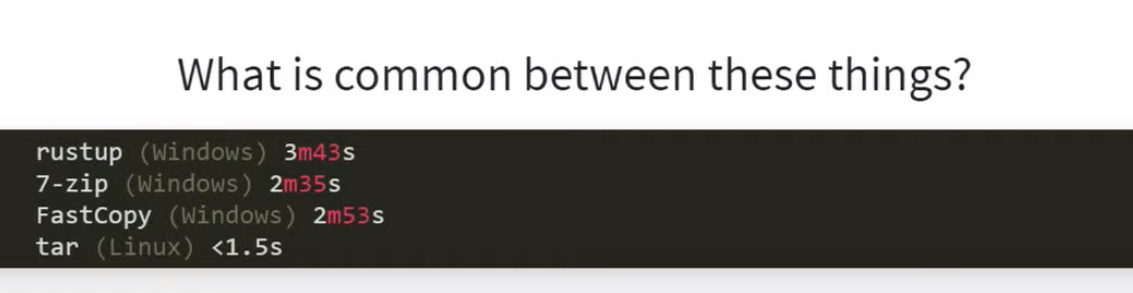
Part of the story is that there’s an internal MS AV API that can skip scanning some types of file on writing/closing, and will only scan the on a (later) read. I suspect it’s something like this that’s responsible for the sudden improvement with a new version of SC after some weeks of MS updates! This is at about 30mins in the talk. With their rustup stuff (after doing some other optimizations) they got equal perf with Linux… but only after MS did their magic on their AV and excluded the rust doc files from being scanned on writing. But still even without that last bit, just with their own threaded-close implementation they went from something like 3m to 11s. And with the MS magic, down to 4s. Alas MS will (probably) not open up that “final magic” AV API…

The MS AV engine really hates HTML files otherwise: 12ms to close one you’ve just written to.
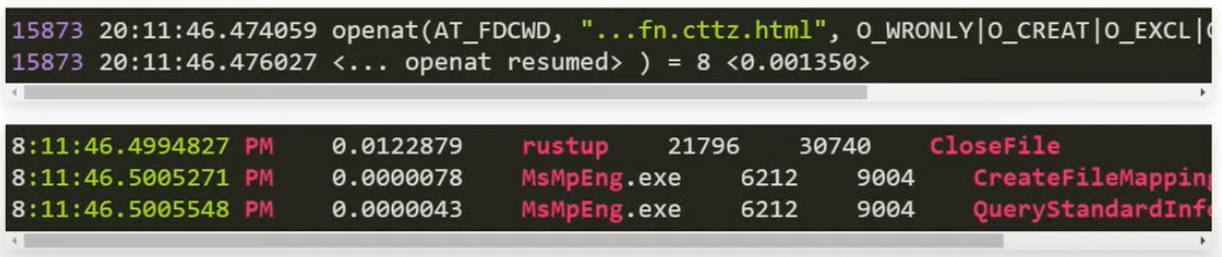
Some experiments on Win 10:
- Turned the MS AV real-time scan off, start SC:
SCDoc: Indexed 2054 documents in 2.92 seconds
- Turn the AV on, forced SC to reindex:
SCDoc: Indexed 2054 documents in 18.37 seconds
- Forced SC to reindex again (AV still on):
SCDoc: Indexed 2054 documents in 3.23 seconds
So, the way the MS AV works now seem to be that it hashes scanned files and won’t scan them again soon thereafter, if they get regenerated with the exact same contents, unless you restart (disable-enable) the AV. The rest of the slowdown compared to Linux is not AV stuff, but probably NTFS stuff, proper.
On Win7 I have Avast installed. (I would not recommend it now because it has become quite “spammy” in its messages compared to how it was some years ago, but I haven’t bothered looking for another AV). Anyway, turning off Avast’s real-time scan saves about 0.7 secs on Win7, getting the reindex time to about 4 secs, still slower than on Win 10. MS apparently did manage a few NTFS improvements over the years.
If you want some confirmation SC startup is seriously dogged by the MS AV, here’s the trace… as you can see it’s not only an issue that MsMpEng (the MS AV) takes most of the time, but it also doesn’t use more than one core, it basically runs “in-process” or something like that.
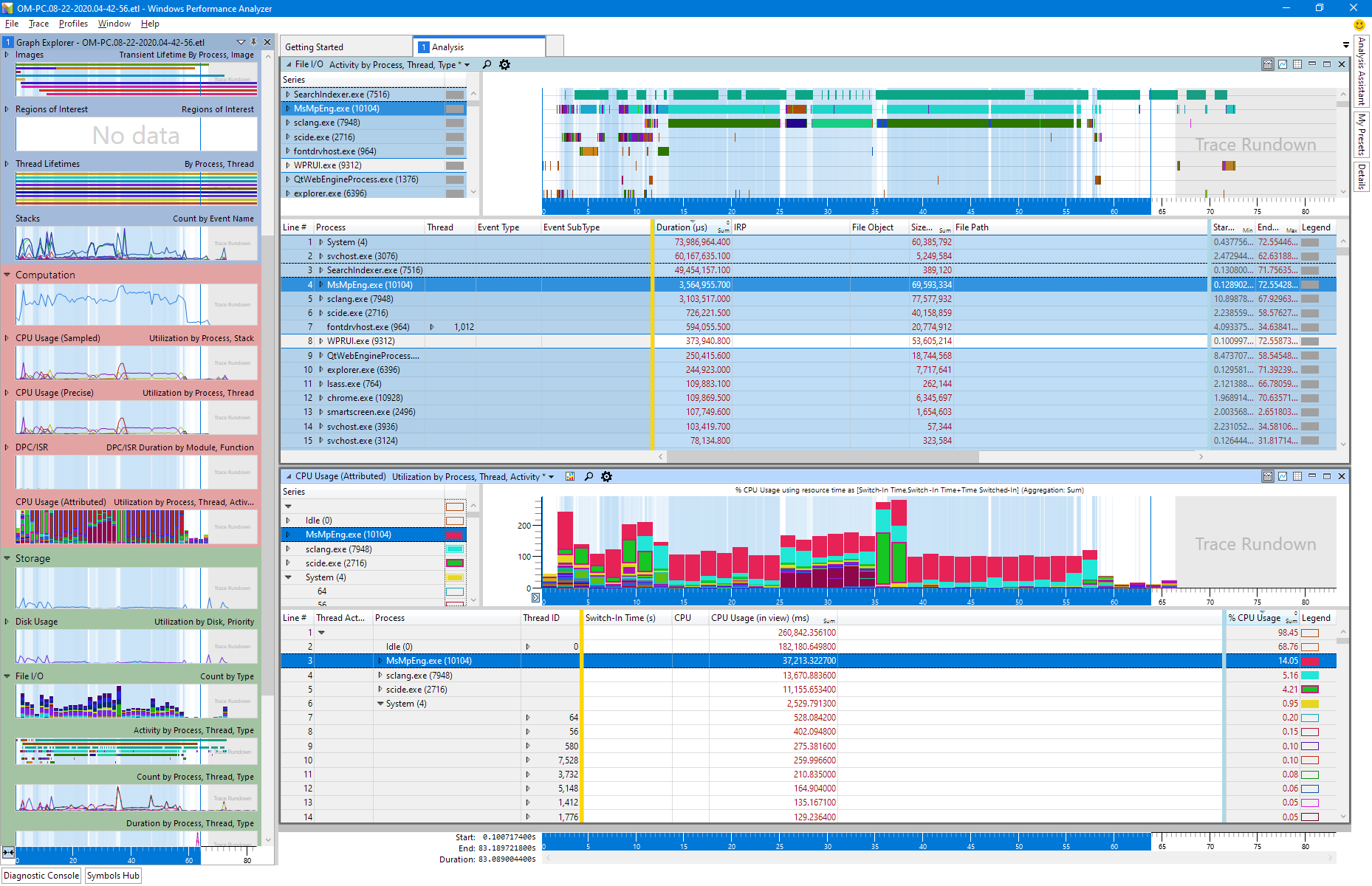
The first part before the big middle spike is the SC class compilation; after the spike is the HTML file generaion. Both a are seriously slowed by the AV (red top part). (Green and cyan are sclang/scide) The dark mauve part (bottom middle) is the only thing I’m not entirely sure what it is; it’s a buch of cmd.exes that run accessing scsyndef files. They are different processes, so it looks like sclang spawns one for each sythdef for some reason. This is not even even with server boot.
Same kind of trace with AV turned off.
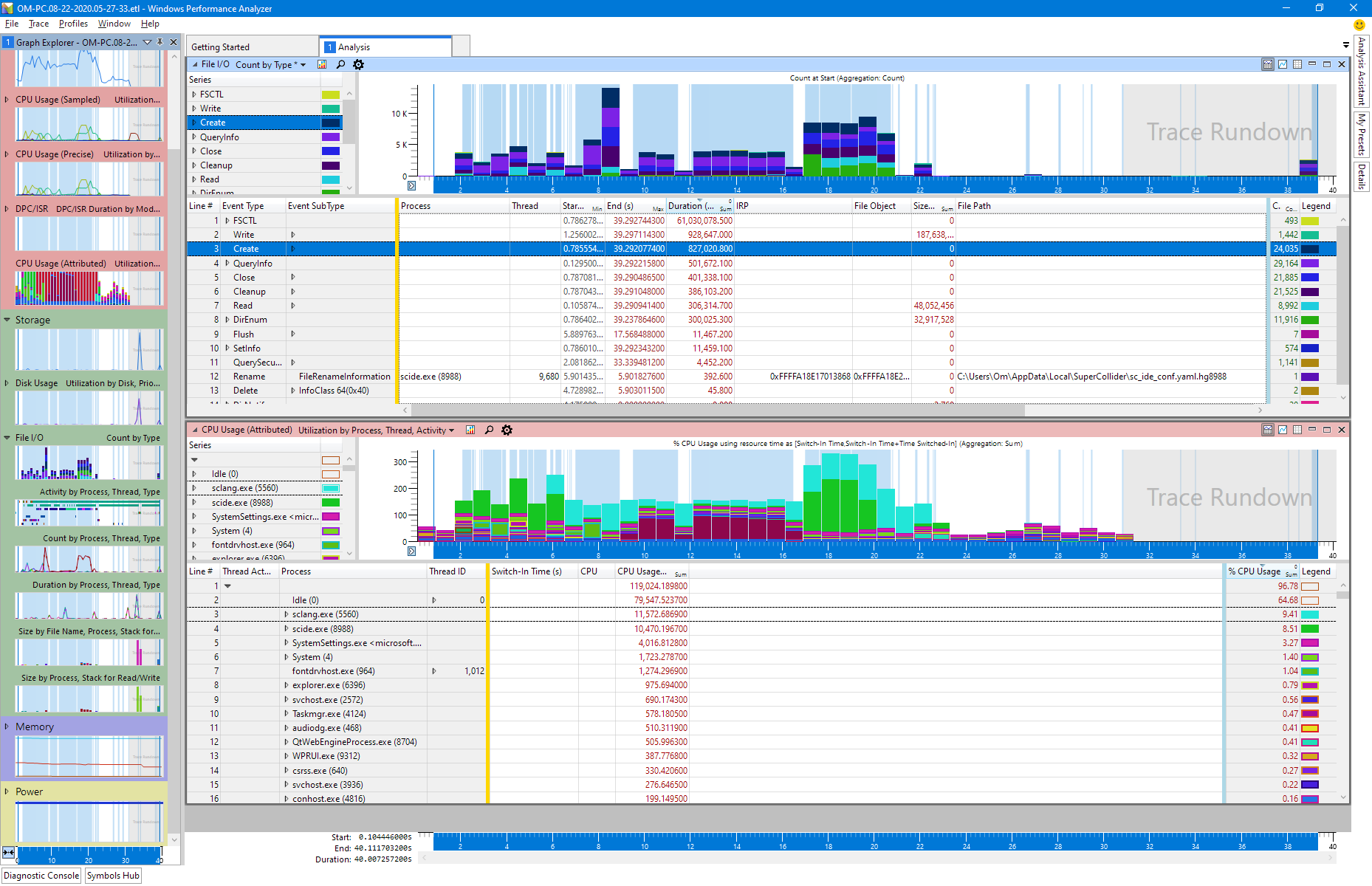
I cannot pin down a single kind of file op that dominates, but the create-stat-close cycles seem to use more kernel time than actual writes.