Also, why do we need block calculation?
// big synthdef, let's compile just once
(
SynthDef(\test, {
var n = 1500;
Out.ar(0, SinOsc.ar(Array.fill(n, { ExpRand(200, 800) })).sum / n)
}).add;
)
x = Synth(\test);
// about 15% with a 64-sample block size
x.free;
s.options.blockSize_(1);
s.reboot;
x = Synth(\test);
// 98-99% with a 1-sample block size
x.free;
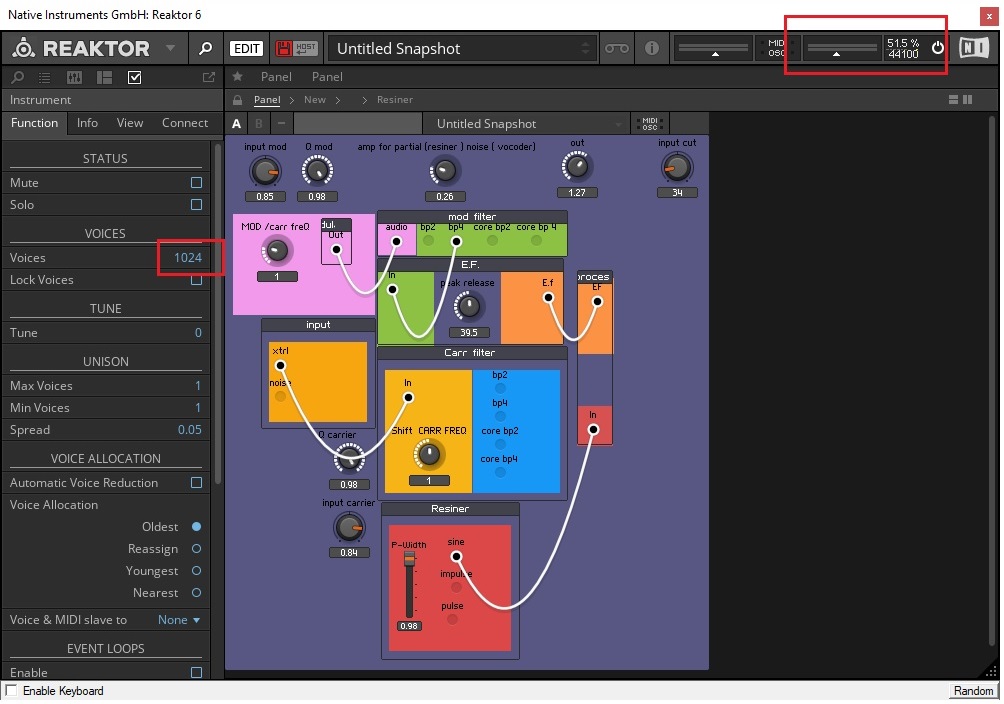
(Reaktor must be doing block calculation, then – there’s no way you would get a thousand sine oscillators on a 10-year-old PC, using only 50% of the calculation time.)
This thread also led me to think about what it would take to have the equivalent of Pure Data’s [block~] (where you can mark part of a patch to run with a smaller block size, for a tighter feedback loop).
The first requirement would be that UGens shouldn’t make any assumptions about a global block size – the next functions should just calculate an input numSamples. It seems the core UGens (except PartitionedConvolution) already do this. I don’t know about sc3-plugins.
It might be fairly straightforward to do it at synth node level – an entire synth (or group?) running with a different block sizes. But usually you just want a small part of a graph to be affected. So it made me think – what would it look like to have UGens that override the block size, and then at the end, reblock to the global setting?
This kind of interface would not work:
Reblock.ar(RLPF.ar(Saw.ar(...), ...), 1)
… because the Saw --> RLPF chamber (presumably) depends on other UGens – the whole tree gets fed into the input. So there’s no clear beginning to the reblocked section. (By contrast, Pd’s [block~] applies to a subpatch or abstraction, which naturally has clear boundaries, and clear [inlet~] / [outlet~] units where the reblocking occurs.)
Un-reblocking(!?) would be easy: EndReblock.ar(signal).
But the beginning… you would need to be sure a hypothetical Reblock.ar() would come up before the first unit to be affected. The only way we can be sure it comes before is by using a UGen input. That would look quite weird, but in theory it would describe the right graph:
arg freq, ffreq, rq; // OutputProxy from a Control
// reblocking instruction, prepared as an input to the Saw
var startBlock = freq <! Reblock.ar(newBlockSize: 1);
var osc = Saw.ar(startBlock);
var feedback = LocalIn.ar(0);
var filter = RLPF.ar(osc, ffreq, rq) + (0.01 * feedback);
var routeBack = LocalOut.ar(filter);
var result = EndReblock.ar(filter);
LocalOut’s input is reblocked so it would have to be, as well.
How to implement that… I don’t know.
hjh