Afaik SOUL is not open source, and the compiler is not available, so there’s currently no way to run it as a UGen (the browser playground works by sending code to a server, which sends back webassembly).
If the compiler were ever made available, it would probably be a very good candidate for writing UGens if it’s modular enough (basically, if you have some flexibility around how you call the audio graph and especially how allocations are done). I’m excited to see how the project progresses. If you want to play with something now, FAUST is a similar project that has been around for a while, and can compile directly to SuperCollider UGens.
Keep in mind, too, that unless you are trying to do short-delay feedback (building custom IIR filters, for example) or some other less ordinary kinds of audio processing, SuperCollider SynthDef graphs are probably flexible enough to do what you want, and are faster than anything you can hand-write or SOUL can compile (unless you, or SOUL, are very good at optimizing audio DSP, which is certainly possible!)
This honestly makes zero sense. What would make sense is to base SC4 on
SOUL as a backend. Or not! They give out binaries and some source, but…
Please note! This set of source files is far from being a complete snapshot of the entire SOUL codebase! The highly complex logic which transforms a HEART program into something actually playable and runs the LLVM JIT backend is still closed-source for the moment (although we’ll be providing binary DLLs with EULAs that allow everyone to freely create SOUL hardware or other playback systems). But as the project moves forward, we’ll be constantly revising and adding to the open source repository.
I’ve recently looked at it, and insofar I’m quite impressed: LLVM JIT compiled “UGen” (process in SOUL) and LLVM JIT compiled interconnect graphs thereof, with claim of hot reload! I have yet to test how well the aspect latter works.
However SOUL code still reads a lot more like C than a high-level language. So having a “ugen interpreter” for a familiar language that spits out SC-style graphs but for the SOUL backend would be useful. I bet a fun project for someone with time is to write a player for SC v2 SynthDefs in SOUL.
Also as of 2021 there’s an experimental Faust backend for the DSP part, i.e. process in SOUL, but seemingly not for the graph interconnect part of SOUL.
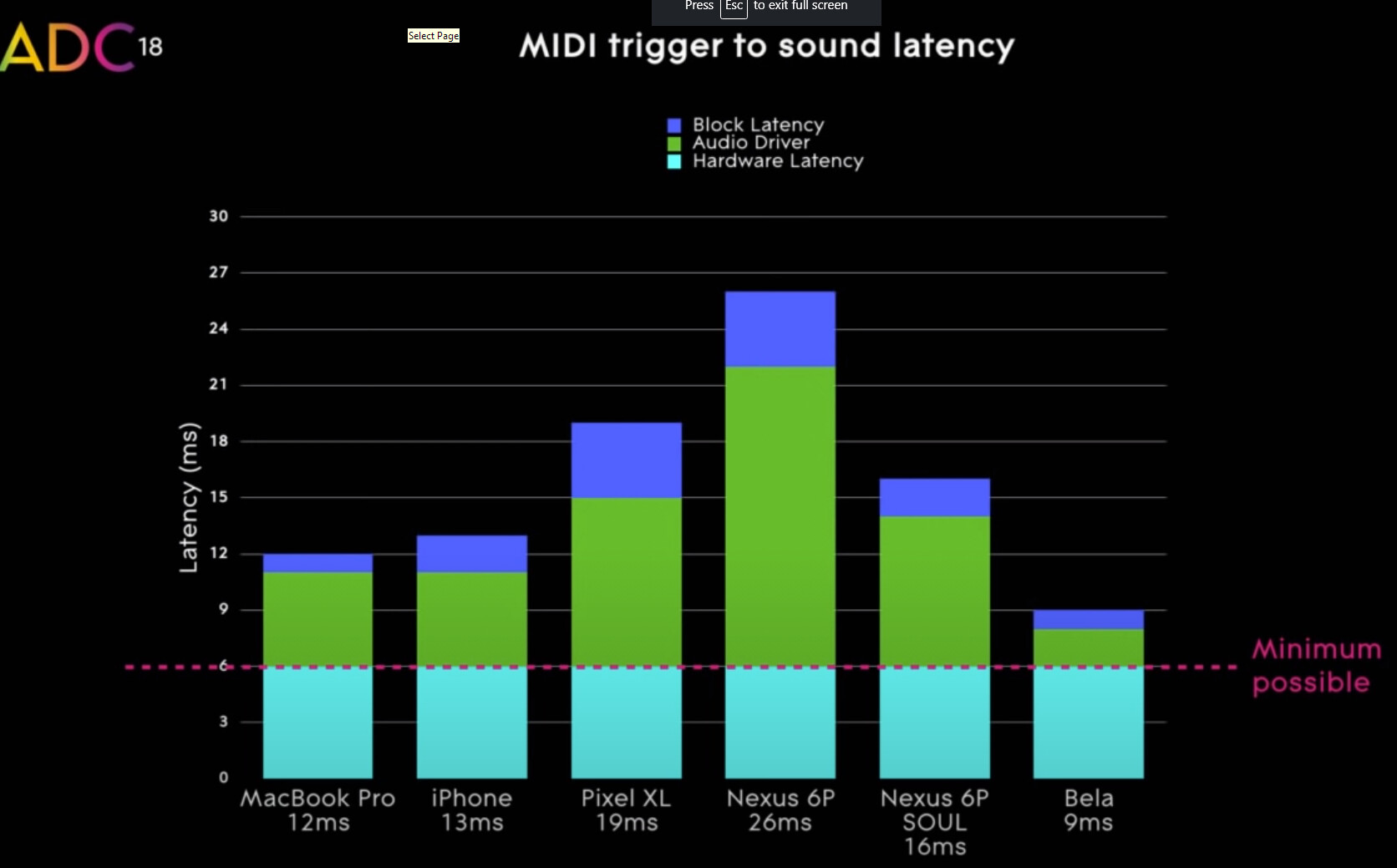
The 2018 ADC talk of the SOUL guy is definitely worth watching though. Not sure how much pull Roli has compared to graphics companies, but if they get their way to have the DSPs in modern devices fairly directly available as GPUs are, it would certainly not matter much that the underlying stuff below the IR is not open source. After all, you send shader stuff to the GPU but its hardware is definitely not open source.
An interesting bit from the talk; they have the SOUL server running on Bela (in kernel), and they claim lower latency than even on Apple hardware. I’d be curious to know what kind of perf SC gets on Bela, latency-wise for comparison, if anyone here has tested that.
The SuperCollider server effectively has two graphs - one that describes a collection of Synths/Groups, and one that describes a collection of UGens that make up a Synth. The first can be mutated in real-time and on a schedule: you can add, remove, and re-arrange nodes while playback is happening, without interruption, with the server handling scheduling, allocation, initialization, etc. The second description is fixed - a SynthDef - and can’t be mutated once it’s created, for performance reasons.
SOUL is built for handling the second thing, but not really the first - so it would be a good candidate for writing UGens, or for building entire SynthDef’s with - just not handling node-level graph stuff, voice management, patterns, etc.
Yeah, I misunderstood what .soulpatch does. Their claim of hot loading that is correct, but the actual graphs in SOUL are defined in the.soul file with graph. And they look pretty static; they are fairly similar to Csound signal flow opcodes, in that regard. There’s no partial reloading of graphs in SOUL, so no hot loading of graph nodes (aka processors in SOUL). So now I feel less sad about SOUL’s demise, as it wasn’t much more than a Faust alternative, with an imperative syntax.
As a side note, another dynamic audio language (with a JIT compiler) is Reaper’s JSFX. Actually, someone already ported it to Pure Data and Max: https://github.com/asb2m10/jsusfx. Of course, it could be also ported to SuperCollider.
JSFX (or EEL2) is a quite nice little language, actually. Some impressive stuff is done with it over at the ReaPack repositories. And I think it will also be supported in one of the next versions of Carla. So yes, would be nice to have it as an option in SuperCollider! Though I think the FaustGen will be even more interesting
Don’t forget Kronos (https://kronoslang.io/), which has a SuperCollider UGen target, supports LLVM compilation, and has some very cool language features. It’s a bit like a more powerful & usable version of FAUST maybe?
The Kronos paper, although 6 years old now, so not covering SOUL, is definitely worth a read just for a “state of the art” summary.
Going back to SOUL a little, I’m surprised they didn’t design for something more flexible in terms of runtime than whole graph replacement, even with their hardware orientation because quoting a nearly random paper from 10 years ago…
Runtime Partial reconfiguration of FPGA is an attractive feature which offers countless benefits across multiple industries. Xilinx has supported partial reconfiguration for many generations of devices. This can be taken advantage of to substitute inactive parts of a hardware systems and adapt the complete chip to a different requirement of an application. This paper describes the implementation of mean and median filters for real time video signal on Virtex-4 FPGA using Partial reconfiguration.
So if one can hot swap video filters at runtime, why not audio ones? Looking at some actual Xilinx docs, it seems the feature is mostly for high-end DSPs though, that they e.g. market for 10 Gb Ethernet. So perhaps it’s not available on cheaper devices, that one might routinely find used in audio, not really sure on that. For instance, it’s not supported on the Spartan-7 series, and also not on single-core Zynq parts. Also this snag, that would not really be acceptable in e.g. a graphics card design nowadays:
Do not use Vivado Debug core insertion features within Reconfigurable Partitions. This flow inserts the debug hub, which includes BSCAN primitive, which is not permitted inside reconfigurable bitstreams.
Here there is a more recent paper on the visual interface “Veneer” for Kronos, we ran a survey study in a supercollider workshop and used it to write uGens. There is also some interesting background review of alternatives and a comparison of features with Kronos/Veneer (for example Multirate DSP, visual interface). Give it a try on the browser and check also the tutorials.
This has been a very interesting read, thank you for posting!
The criticism in the paper of the limitations of UGen based languages made me think again how nice the concept of a JIT compiler inside SuperCollider for a language like Faust is: you can do the prototyping without “leaving” SuperCollider and later compile tbe result to a class. So any such capabilities for other potential canditates like Kronos or SOUL would of course be an enhancement. (Or JSFX, though that one for sure won’t be able to be compiled to UGens.) And all this would give the chance to easily work with the DSP capabilities of those languages while using all the pattern etc. capabilities of SuperCollider.
Maybe this is something that belongs into the SuperCollider 4 discussion thread: the mindset of using several closely interlocked languages, each focussing on what it does best.
Concerning Kronos: How active is the development of this project by the way? The latest news on the homepage are from late 2020 and the Github seems to have fallen quite silent this year too…
@Hyppasus Is there a discussion forum or even old-school user mailing list for Kronos? I only see a newsletter option on their site. Granted, some academic projects don’t want that kind of complication… having to deal with users.
Also worth noting is that it doesn’t seem to be open source, but only free as in free beer.
The documentation from the PhD thesis is a bit outdated. The method for selecting audio out from there doesn’t work anymore. But if you have ASIO drivers installed krepl seems to pick the first one… so I could make this work “zero config” to make it make noise on my machine
> Import Gen
> snd = Wave:Saw(440)
> snd = 0
The last one is to turn it off
The design of the sound server appears extremely basic, looking at the thesis, just a sound pipe, no nodes, groups or anything like that. Just puts out whatever is in snd. All the smarts are in the JIT and the objects it instantiates. I’m honestly not too sure how it differs from Faust on this level. I’ll have to dig a bit deeper on how replacement at runtime is done, if it’s possible. If I just do something like
Yes, it seems like is mostly an academic project (albeit a good one!) that never really had much of a wider user/maintainer base.
Unfortunately, this seems like a natural outcome - the group of people interested in hacking on deep DSP algorithms but aren’t comfortable doing that in C++ seems like a small-ish population, and that ecosystem is mostly monopolized by Faust already.
I’m curious if anyone has recent experience with Faust’s performance? Last time I looked at it (years ago), it was only relying on compiler for vectorization, which usually means… it’s doing very little vectorization at all, making it not really competitive with anything hand-coded, or most of the built-in SC UGens. Faust as a language has lots of potential to improve this, but I just don’t follow the project closely enough to know if the work as been done…
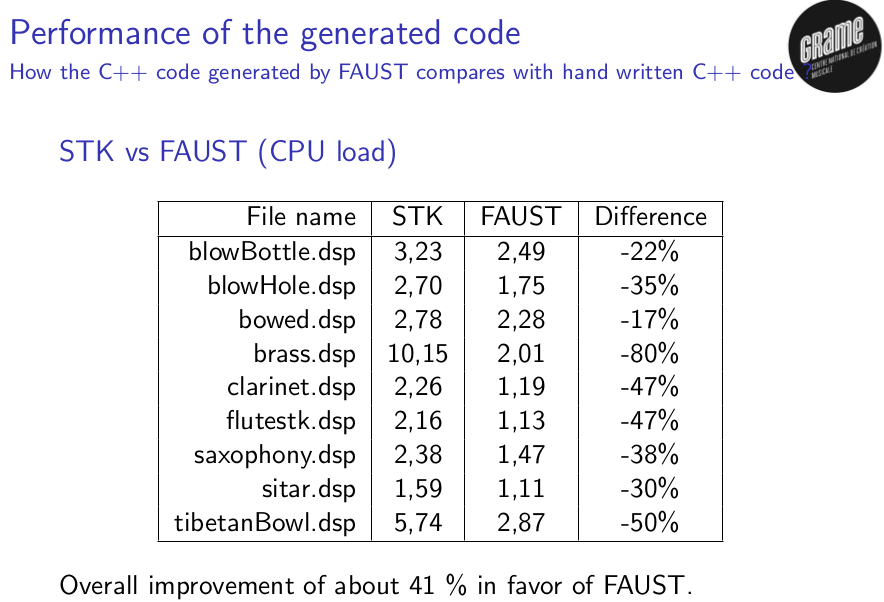
According to the Faust papers of some 15 years ago (don’t have the ref handy, sorry) they were easily beating hand-written C++ code like STK. Not so sure about vectorization for wider, more recent architectures, 256-bit, 512-bit etc.
Here’s a slide from one of their talks, since I can’t find that paper again.
GPU/CPU memory transfer suffers from high latency, so is not adapted to real-time computation with small buffer sizes
There’s a more recent paper on that at NIME 2020, not related to Faust though. "There and Back Again: The Practicality of GPU Accelerated Digital Audio ". Apparently, if you use built-in GPUs, the latency issue is less bad, but they suffer from lower (bandwidth) performance, of course. What would also be interesting but is missing from that last paper is a comparison between GPU and AVX. At what point is it worth crossing over?
(Also worth noting some typical Intel $#!!%@#!!!$%!!@# of late, support for AVX-512 in non-server processors is absolutely haphazard. By this I mean: good luck programming for that byzantine compatibility matrix, especially when you factor in the downclocking that is applied on some models when 512-bit instructions are used. So there are talks like “Mitigating AVX-Induced Performance Variability with Core Specialization”. At this point it’s worth asking: how is this different from using an on-die GPU?)
Just watching the wheels of it, the problem might be that the development is done with mercurial as cvs, the license of the kronos dsp compiler says gpl3 …